Building a data pipeline with Mage, Polars, and DuckDB
GitHub Repo: SODA to DuckDB

Where are we in the data lifecycle?
As data analysts or scientists, we often find ourselves working downstream in the data lifecycle. Most of the time, our role involves transforming and analyzing data that has already been prepared and served to us by upstream processes. However, having a deeper understanding of the entire data pipeline—from ingestion to transformation and storage—can empower us to optimize workflows, ensure data quality, and unlock new insights.
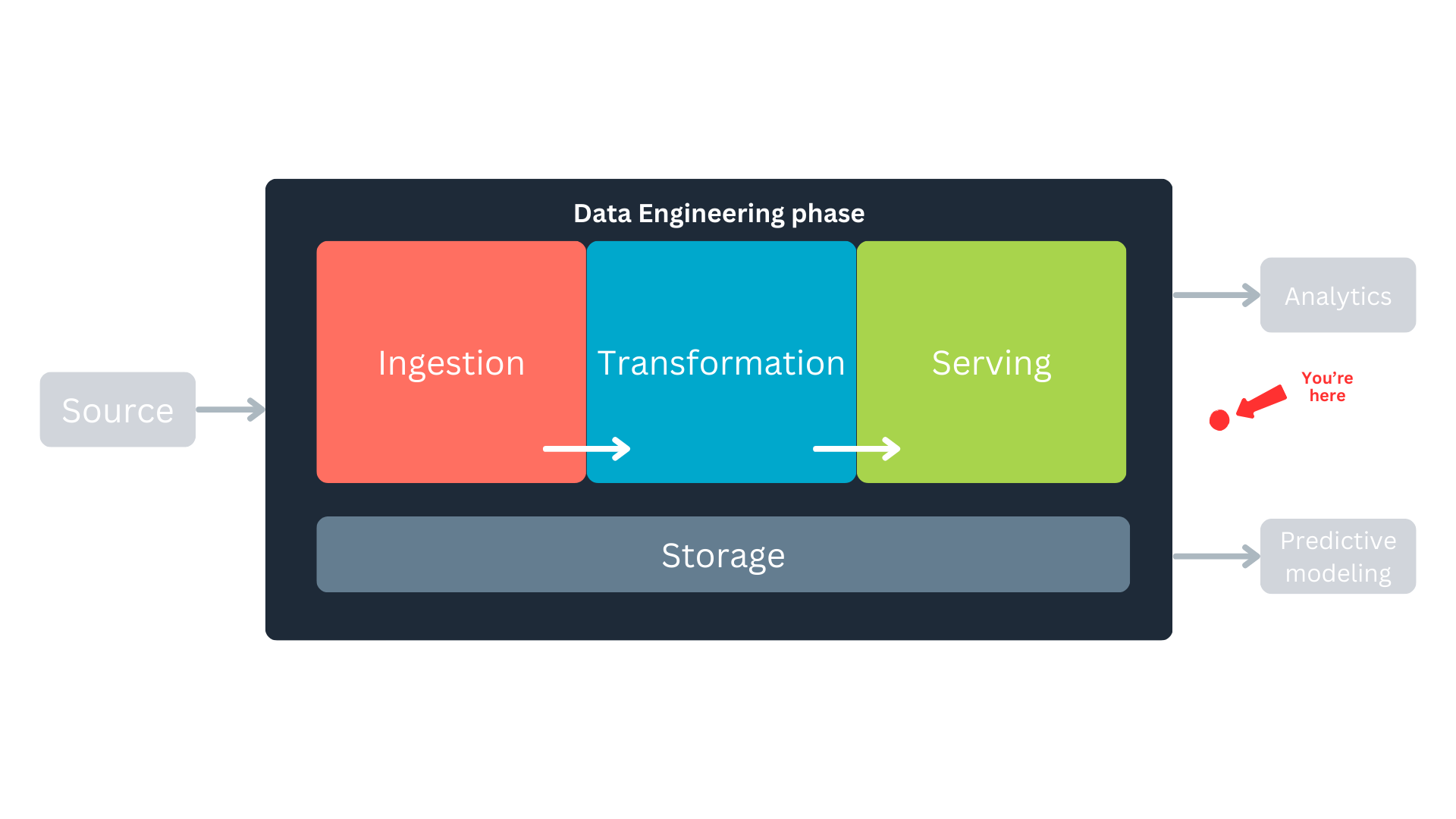
Another advantage of gaining understanding—and hands-on experience—in data engineering processes is the empathy we build with our data engineers. These are the colleagues we work closely with and rely on, making a strong, collaborative relationship essential. Hence, in this hands-on article, we will explore the Python ecosystem by examining tools such as Mage, Polars, and DuckDB. We’ll demonstrate how these tools can help us build efficient, lightweight data pipelines that take data from the source and store it in a format that is well-suited for high-performance analytics.
About the tools
In this project, we will use Mage as our data orchestrator. The tasks the orchestrator manages will include data fetching, manipulation and transformation using Polars, and persistent storage with DuckDB.
What are data orchestrators?
Data orchestrators, such as Mage, are tools that help manage, schedule, and monitor workflows in data pipelines. They allow us to automate complex processes, ensuring that tasks are executed in the correct order and dependencies are handled seamlessly. By using Mage as our orchestrator, we can streamline our data pipeline and focus on building efficient workflows that allow us to set a local database appropriate for our analysis.
Data manipulation and storage
Why Polars and DuckDB? The answer lies in the size and nature of the dataset we’re working with. Since our dataset is small enough to fit in memory, we don’t need a distributed system like Spark. Polars, with its fast and memory-efficient operations, is perfect for data manipulation and transformation. Meanwhile, DuckDB provides a lightweight, yet powerful, SQL-based engine for persistent storage and querying. Together, these tools offer a simple, performant, and highly efficient solution for handling our data pipeline.
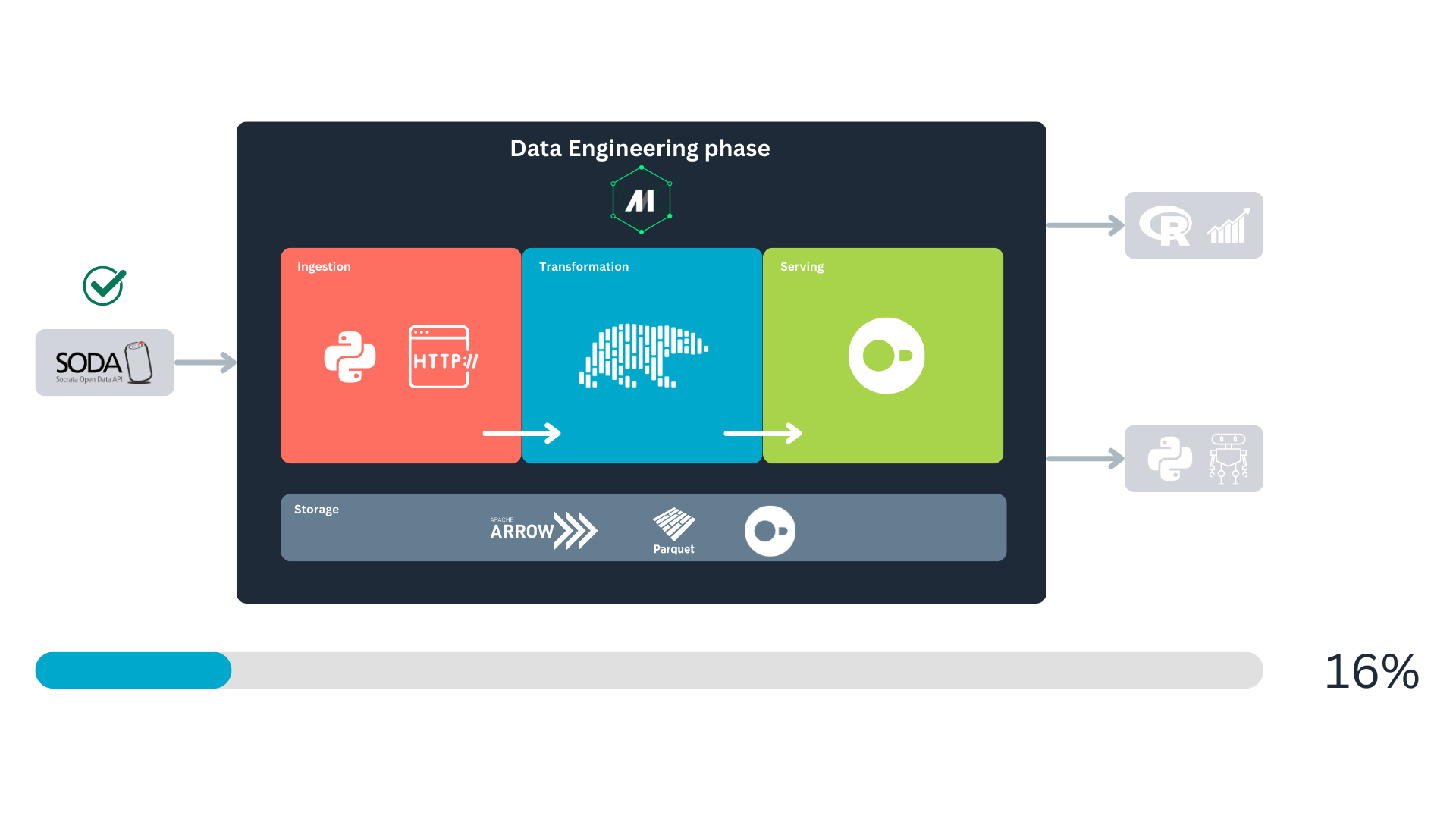
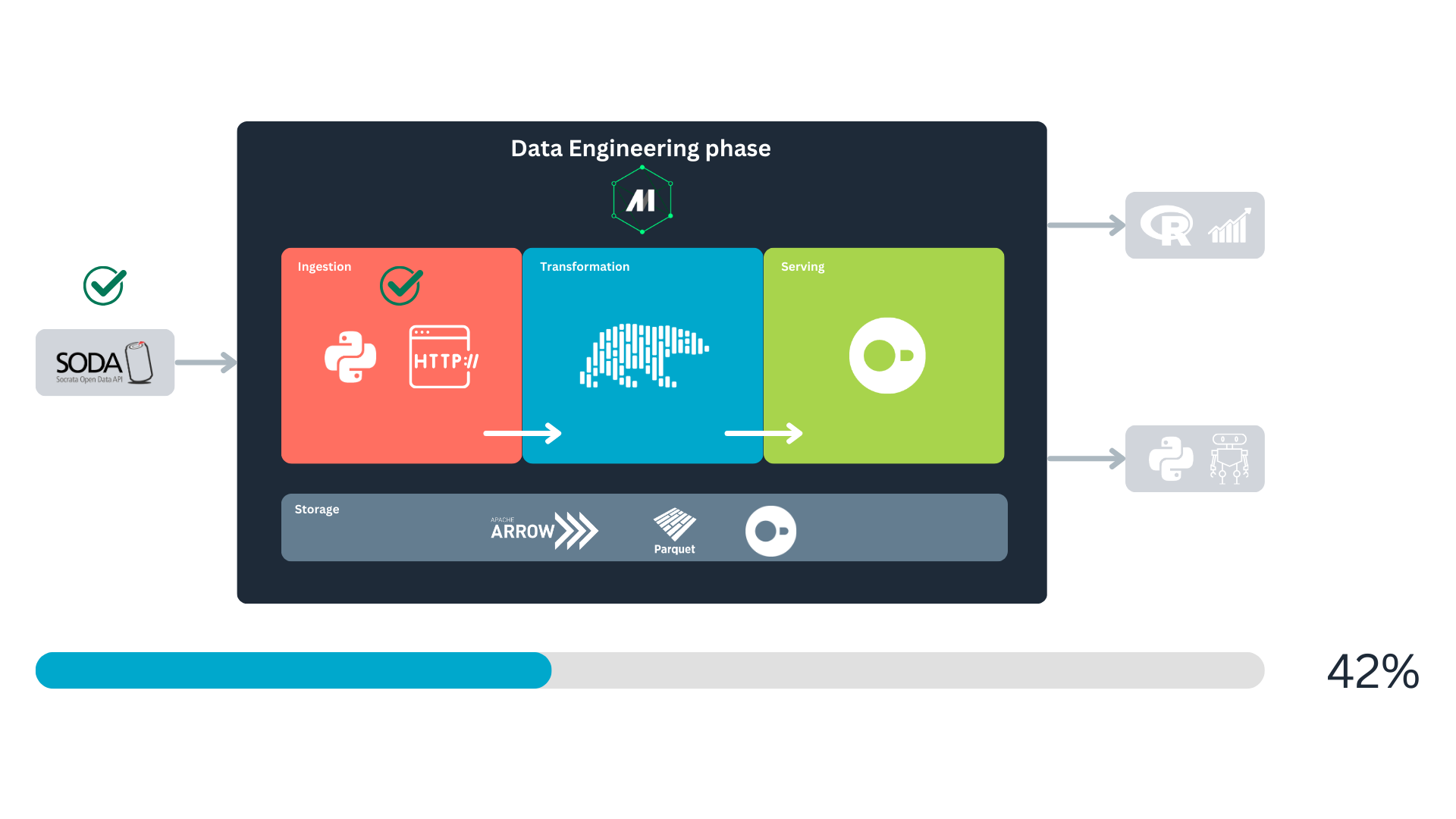
Returning to the data lifecycle diagram, we can land it in a more concrete way to show how our project will be built and executed:
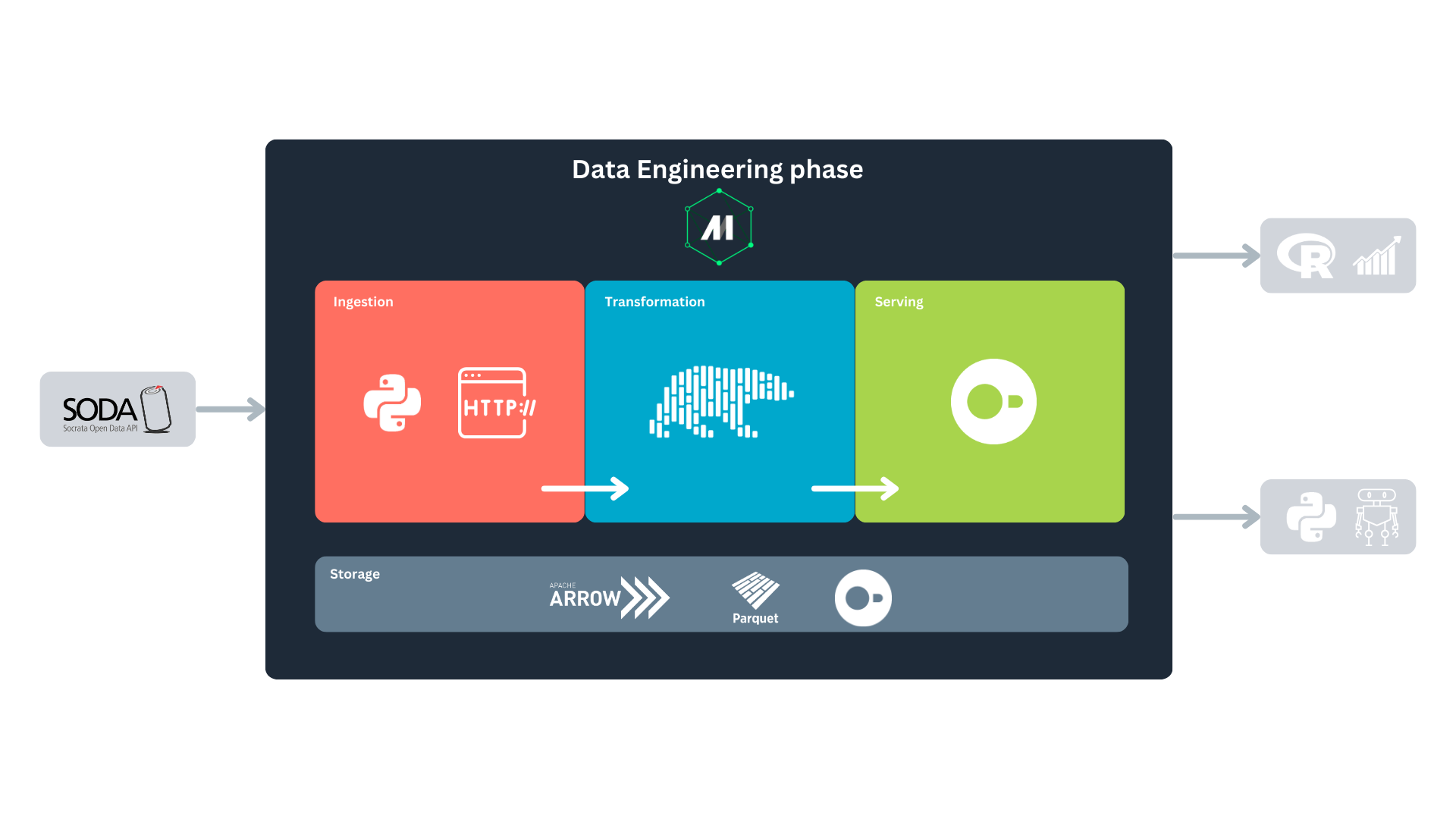
First, we will fetch the data from the Socrata Open Data API (SODA) through HTTP. After that, we will generate some extra variables of our interest with Polars, to finally store it in a DuckDB database. We will consume this database for analytics and predictive modeling. All this is orchestrated with Mage.
Tools and resources overview:
- SODA API: provides access to open datasets, serving as our data source. It contains “a wealth of open data resources from governments, non-profits, and NGOs around the world1.”
- Mage: the data orchestrator that will automate and manage the pipeline.
- Polars: a high-performance data frame library implemented in Rust, ideal for fast data manipulation.
- DuckDB: a columnar database system designed for efficient analytics and in-memory processing.
- uv: a fast Python package and project manager that creates the project environment, installs dependencies, and keeps the dependency lockfile reproducible.
We’ve chosen the Iowa Liquor Sales dataset since it is big enough to make this ETL (extract, transform, load) pipeline interesting.
Our problem
Let’s say we work for a big chain of liquor stores located in the US, Iowa. Part of the intelligence in your company is built upon the information made available through SODA API, and it feeds some of the dashboards the decision-makers consume. You also use it often to do research and predictive modeling. Some stakeholders have started complaining about the loading times of the dashboards, and you have also been a little frustrated with the time it takes to get the data to train your predictive models.

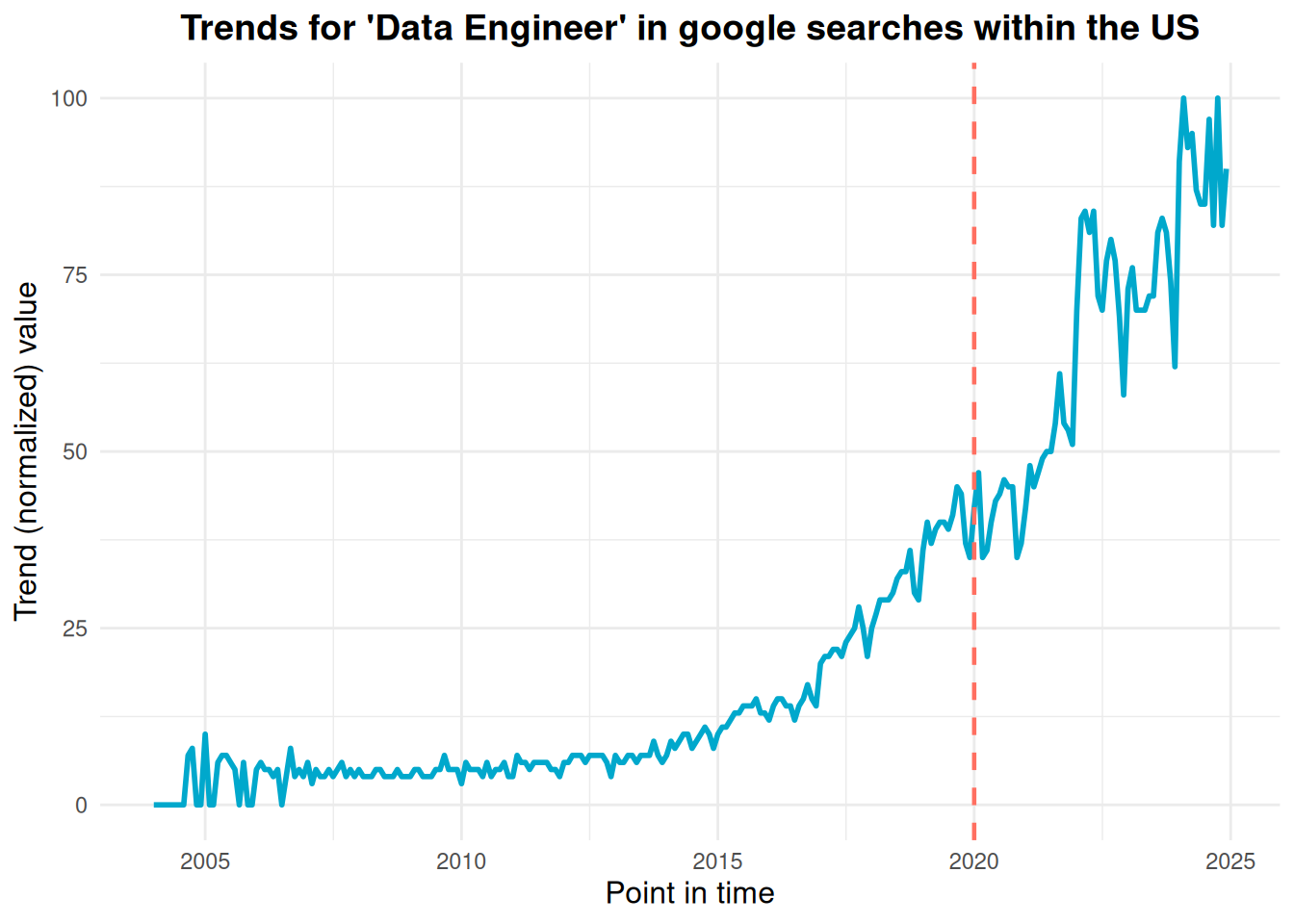
To continue building our situation, let’s imagine the year 2020—when the term “data engineer” was not as popular as it is today. You’ve just been hired as a data analyst2, and according to Google Trends, the term “data engineer” was only half as popular as it is now. Moreover, a closer look at the trend data from 2020 reveals that most searches for this term originated in tech hubs like California or Washington rather than in states like Iowa.
At this point, you know you are on your own to optimize this process3. And you already have a clear outline for this process:
- Pull the data from the API.
- Generate the variables that provide the most valuable insights for the team️.
- Store the data in a location that allows for easy and fast retrieval .
This brings us to our current challenge: finding a more agile and efficient way to make the SODA liquor sales data accessible to the rest of the company.
Solution implementation: getting started
As outlined earlier, the first step involves pulling the data from the API. However, before that, we need to set up Mage and configure the rest of our environment. To begin, we’ll clone the Git project and navigate to the project directory:
git clone https://github.com/jospablo777/mage_duckdb_pipeline.git
cd mage_duckdb_pipelineThis project uses uv to manage the Python environment and dependencies. Instead of creating a virtual environment manually and installing packages with pip, we let uv read the project’s pyproject.toml and uv.lock files, create the .venv directory, and install the pinned dependency set.
The project intentionally uses a narrow Python and dependency range. At the time of writing, the relevant pyproject.toml section is:
[project]
name = "mage-duckdb-pipeline"
version = "0.1.0"
description = "SODA to DuckDB: building a data pipeline for high-performance analytics with modern tools"
readme = "README.md"
requires-python = ">=3.12, <3.13"
dependencies = [
"duckdb>=1.5.2",
"mage-ai==0.9.75",
"pandas==2.2.3",
"scikit-learn>=1.5,<2",
"skforecast==0.22.0",
]Notice three things. First, we restrict Python to the 3.12 series because this project was tested in that runtime. Second, mage-ai is pinned to 0.9.75, while DuckDB allows compatible newer versions starting from 1.5.2. Third, the forecasting section below uses skforecast with a scikit-learn estimator, so those modeling dependencies are also captured in the project definition. The exact versions installed in your environment are recorded in uv.lock, so collaborators and future runs can recreate the same working setup.
If you do not have uv installed yet, install it first:
curl -LsSf https://astral.sh/uv/install.sh | sh
uv --versionNow sync the project environment:
uv syncThis command creates the project’s .venv folder if needed and installs the dependencies resolved in uv.lock. In day-to-day use, this is the main command you need after cloning the repository.
When adding or changing dependencies, use uv add so that pyproject.toml and uv.lock stay in sync. For example, the core dependencies can be expressed as:
uv add "mage-ai==0.9.75" "duckdb>=1.5.2" "pandas==2.2.3" "scikit-learn>=1.5,<2" "skforecast==0.22.0"
uv syncIf you update a dependency later, update the lockfile deliberately. For example:
uv lock --upgrade-package duckdb
uv syncNow that the project environment is ready, we can start Mage through uv run:
uv run mage startThis will open a tab in our web browser that looks like this:
One of Mage’s greatest strengths is its intuitive user interface. It allows us to easily create and manage data pipelines. In this example, we’ve named our pipeline socrata_iowa_liquor_pipeline. Once the pipeline is created, we can navigate to it using the left panel, then go to the Pipelines section, where our newly created pipeline will be listed, click on it.
After opening the pipeline, navigate to the Edit pipeline section in the left panel, identified by the </> symbol. This is where we can begin constructing our pipeline. Here, you will have the option to insert a block:
Our objective is to build the following pipeline using a series of different blocks:
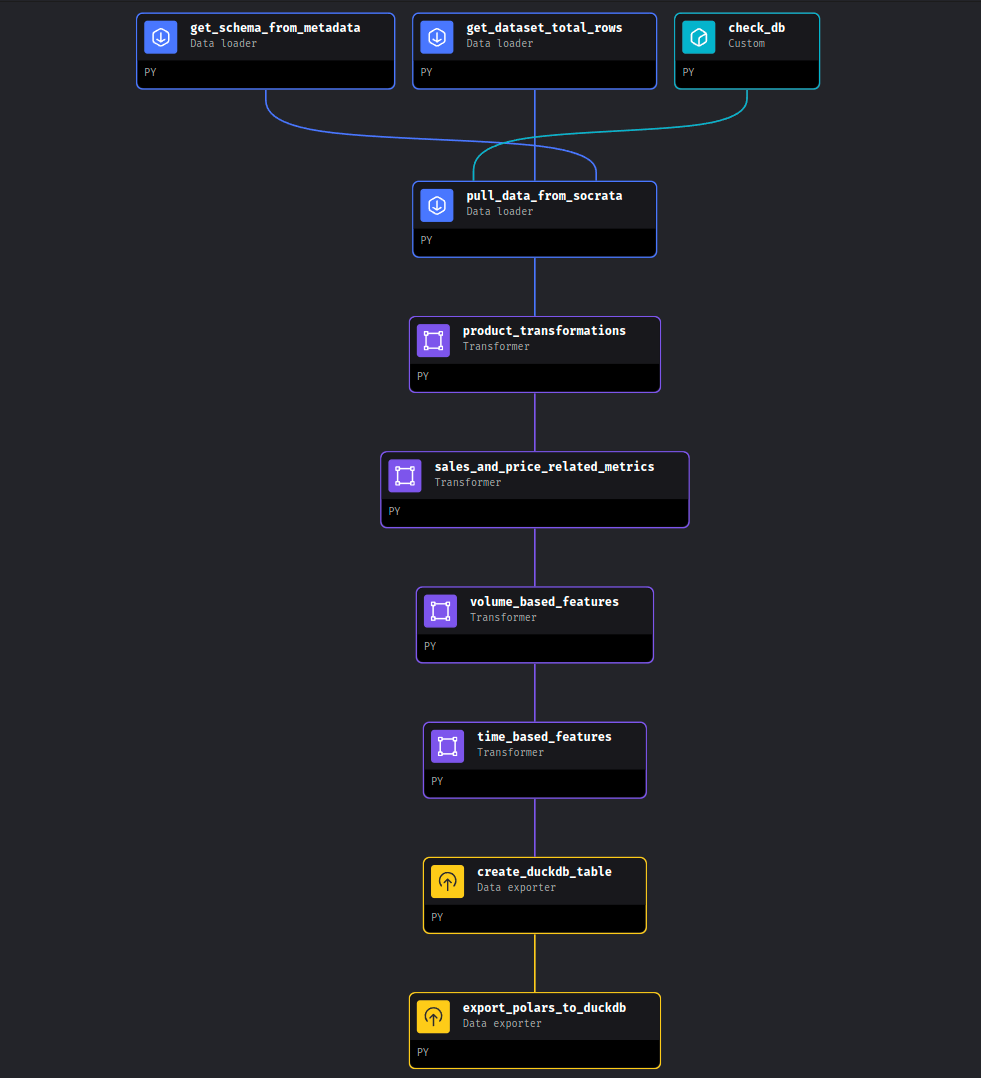
Great! Now that our environment is set up and we’ve familiarized ourselves with Mage’s user interface, let’s take a closer look at our data source: the Iowa Liquor Sales dataset. We’ll return to Mage shortly.
SODA API: our data source
The Iowa Liquor Sales data is provided by the Iowa government through the Socrata Open Data API (SODA), a platform designed to grant access to open datasets from government agencies, non-profits, and other organizations. This API allows us to programmatically interact with our dataset of interest, enabling us to retrieve data via HTTP requests.
The dataset’s documentation provides the key information needed to access the data: the source domain (data.iowa.gov) and the dataset identifier (m3tr-qhgy). With this information, we can define the endpoint for sending our requests. The documentation also details the available variables and their respective data types. Below is an example of a base endpoint for this dataset:
https://data.iowa.gov/resource/m3tr-qhgy.csvThe dataset documentation also informs us that, to date, it consists of more than 30 million rows and 24 variables. Now that we know the endpoint and the size of the data, we’re ready to pull the data, right?
A sensible approach would be to retrieve the data sequentially using the paging method described in the SODA documentation. This method allows us to fetch the data in manageable batches, specified by the $limit parameter, while navigating through the dataset using the $offset parameter. The process is illustrated in the following diagram:
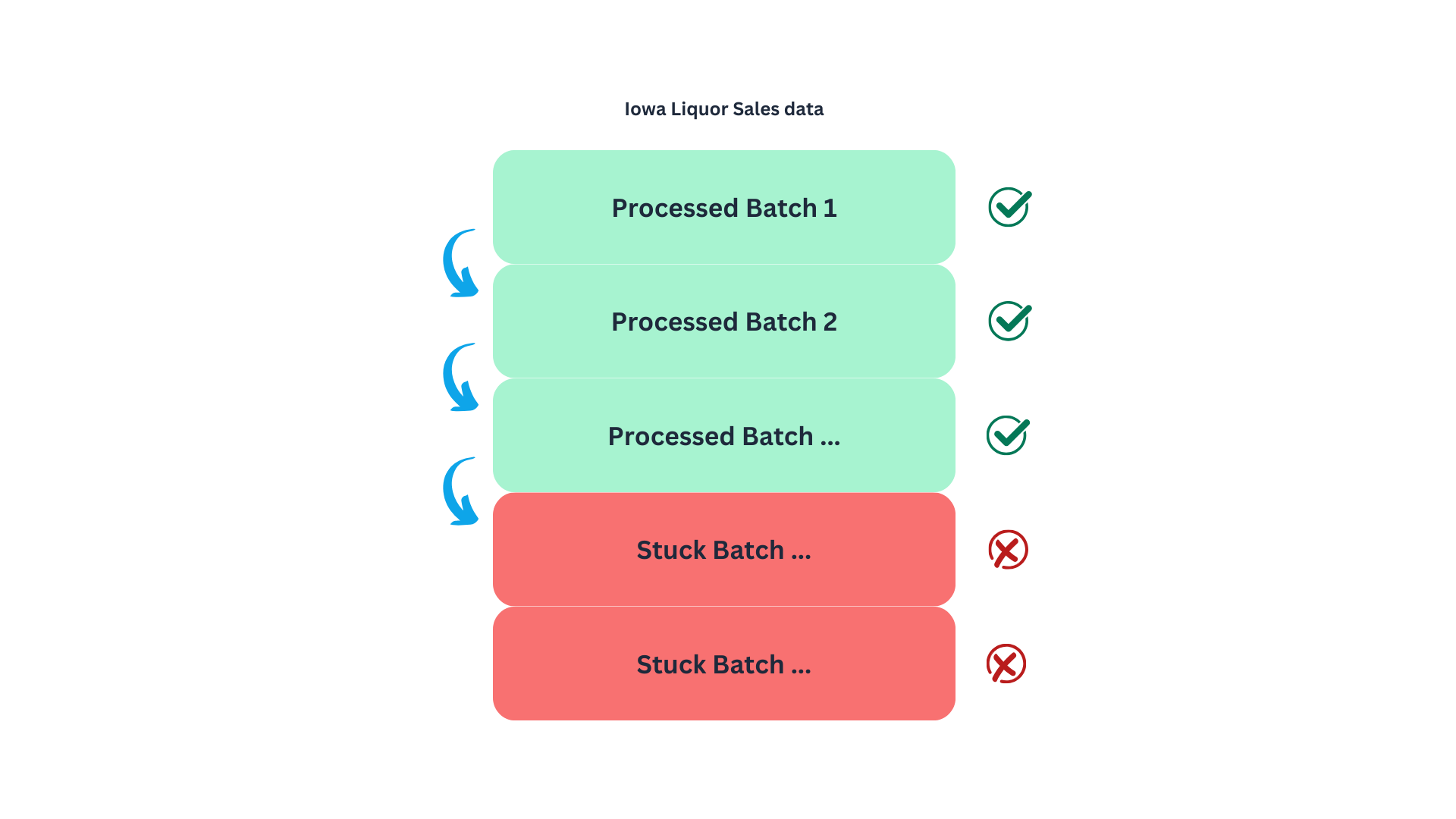
Naturally, I started with this approach to find a limitation in the API that was not documented. When we get to the point of pulling the records around row 20M, the data loader will get stuck, and no information will be pulled. This might be by design or due to system limitations in which deep paginations can bog the system4, making this an unreliable method to get the data5. Meaning that we will need a different strategy to retrieve the 30M records.
This brings us to the next strategy: using SoQL, the query language of the Socrata API. SoQL is quite similar to SQL, with the key difference that its syntax is structured to work within a URL format.
We will send an HTTP request to the server to query individual batches of invoices corresponding to a specific year (based on the date variable). We represent this as follows.
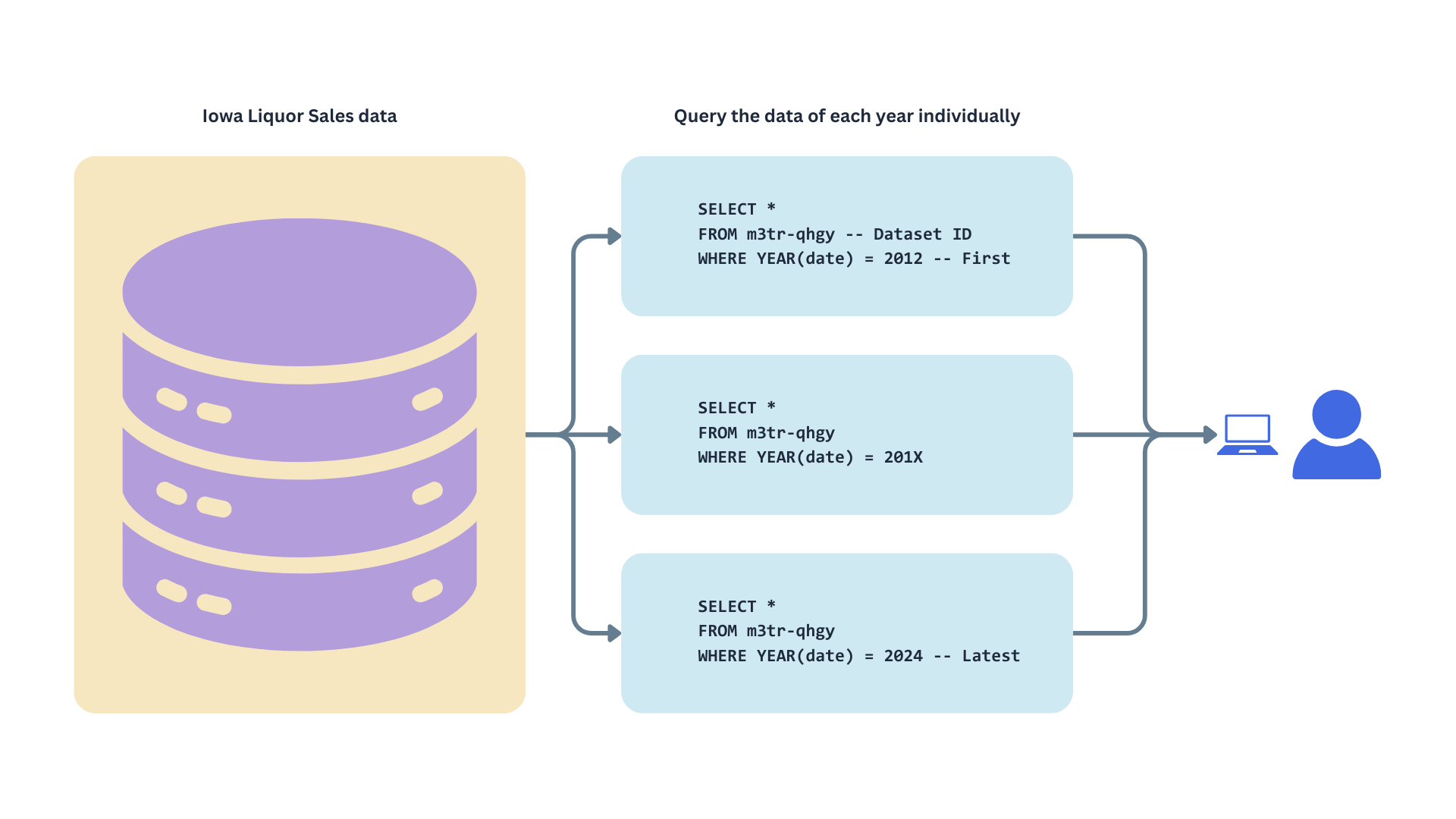
This approach limits pagination to the number of years in the dataset rather than the total number of records. By fetching data in yearly batches, our requests won’t get stuck at an offset of 20 million, as each year contains fewer than 3 million records.
Why are we spending so much time on this? Understanding our data source’s quirks, perks, and limitations is crucial because, ultimately, this knowledge will shape how we design our data pipeline. So it’s worth it to spend some time understanding the source system; it will save us headaches and result in a better design that is easier to maintain from the beginning.
Now, we have a clearer understanding of the upper stage in our stream, the data source.
With this in mind, we can now move on to the ingestion step.
Fetching the data
We are aware of the endpoint to request the data and some limitations of this API. We know that we cannot fetch the data as it is because, at some point, our pipeline will clog, and we won’t be able to request more data from the SODA DB.
Due to this, we will write more complex HTTP requests using SoQL, the SODA query language. SoQL syntax is similar to SQL, so if you are familiar with relational databases, learning will feel intuitive.
Our base query to fetch the data will look something like this:
https://data.iowa.gov/resource/m3tr-qhgy.csv?$where=date_extract_y(date)=2013&$limit=2000
- Teal: the endpoint for the data request.
- Blue: the
WHEREclause of the SoQL query, used to filter records for the year 2013. The functiondate_extract_y()extracts the year from thedatecolumn. - Orange: the
LIMITclause of the SoQL query, used to limit the response to 2000 records. If we don’t indicate this, the default will be used, which is 1000 records.
Notice that the ? symbol separates the endpoint from the query parameters, and each clause is separated by an & symbol. To indicate the start of a clause, a $ is used.
This request will be sent using the GET HTTP method.
With this in mind, we can return to Mage. We’ll begin by creating the first three blocks, which will focus on retrieving metadata. The primary purpose of these blocks is to provide the downstream block with the necessary information on what data to fetch from the endpoint and how to fetch it.
Note
In this tutorial, we will adopt the writing style of The Rust Programming Language book, where the file path is shown before each code block. This approach allows you to easily follow the project’s structure. The complete code for the project is available on the GitHub repo. Also, the function docstrings have been removed from this article. However, you can review the complete technical documentation of each function by checking the files in the repo.
Writing our first Mage blocks
Here we will implement our first blocks, two of them will fetch metadata from the SODA API, and another one will get metadata from our local database (DuckDB). First lets go to our already created pipeline, socrata_iowa_liquor_pipeline. If you want to follow this tutorial from scratch, you can create a fresh pipeline (for instance, socrata_iowa_liquor_pipeline_from_scratch) and continue from there. With the intuitive Mage UI, it will be easy for you to create this new pipeline.
Our first block:
Here, select the first option, Data loader, then navigate to the creation option and select Python as the language, and then API as the source, then name the block get_schema_from_metadata. When created, the block will come with a template like this:
Filename: data_loaders/get_schema_from_metadata.py
1import io
import pandas as pd
import requests
if 'data_loader' not in globals():
from mage_ai.data_preparation.decorators import data_loader
if 'test' not in globals():
from mage_ai.data_preparation.decorators import test
2@data_loader
def load_data_from_api(*args, **kwargs):
"""
Template for loading data from API
"""
url = ''
response = requests.get(url)
return pd.read_csv(io.StringIO(response.text), sep=',')
3@test
def test_output(output, *args) -> None:
"""
Template code for testing the output of the block.
"""
assert output is not None, 'The output is undefined'- 1
- Imports: block’s prelude.
- 2
-
Main functionality: since this is a data loader it has the
@data_loaderdecorator on top. - 3
- Test for data validation: accepts the output data of the block. If any of the tests fail, the block execution will also fail.
Mage provides a variety of templates designed to guide you and save time. These templates were incredibly helpful when we6 first started building data pipelines. Notices the structure of a block, it is composed by three sections: library imports, a function, and a test. The function handles the main task of the block, while the test ensures that the block’s main functionality works as intended.
Next, we’ll modify the template to suit our specific use case. Overwrite the content of your newly created block with the following code, and let’s proceed to analyze it:
Filename: data_loaders/get_schema_from_metadata.py
import io
1import polars as pl
2import requests
if 'data_loader' not in globals():
3 from mage_ai.data_preparation.decorators import data_loader
if 'test' not in globals():
4 from mage_ai.data_preparation.decorators import test
# Map API data types to Polars types
5SODA_TO_POLARS = {
"text": pl.Utf8,
"number": pl.Float64,
"calendar_date": pl.Datetime("us"),
"floating_timestamp": pl.Datetime("us"),
}
# Loads the schema (i.e., types) of our data set
6@data_loader
def load_data_schema_from_api(*args, **kwargs):
7 url = 'https://{DOMAIN}/api/views/{DATASET_ID}'.format(**kwargs)
response = requests.get(url)
metadata = response.json()
columns = metadata.get("columns", [])
schema = {
8 col["fieldName"]: SODA_TO_POLARS.get(col["dataTypeName"], pl.Utf8)
for col in columns
9 if not col["fieldName"].startswith(":@computed_")
}
return schema
10@test
def test_output(dictionary, *args) -> None:
assert dictionary is not None, "The output is undefined"
assert isinstance(dictionary, dict), "The output is not a dictionary"
assert len(dictionary) > 0, "The dictionary is empty"- 1
- Polars: used for data manipulation and type mapping throughout the project.
- 2
-
HTTP library:
requestsis used to send HTTP requests to the API. - 3
-
Loader decorator: the
@data_loaderdecorator marks the function as a Mage data loader block. - 4
-
Test decorator: the
@testdecorator defines a test function for validating the output. - 5
-
Socrata to Polars type mapping: the
SODA_TO_POLARSdictionary maps Socrata data types to corresponding Polars types, ensuring compatibility. - 6
-
Function decoration: the loader function
load_data_schema_from_apiis decorated with@data_loaderto integrate it into the Mage pipeline. It is important to include the decorator to power the function we define with Mage functionalities. - 7
-
Endpoint definition: the endpoint URL is dynamically generated using the global variables
DOMAINandDATASET_ID. This is where the schema metadata is fetched. - 8
-
Dictionary comprehension: the
schemadictionary maps column names to their corresponding Polars types, based on theSODA_TO_POLARSdictionary. Unrecognized types default toUtf8. - 9
-
Exclusion columns: columns with names starting with
:@computed_are excluded from the schema. - 10
-
Test function: the test validates the loader’s output, ensuring it is a non-empty dictionary of the correct type. Remember to include the
@testdecorator so the test works as Mage intended.
The primary goal of the get_schema_from_metadata block is to retrieve data type information to standardize batch ingestion. While Polars can infer data types based on the content it reads, each batch may differ in structure. This inconsistency can lead to errors and prevent us from merging batches later. We can resolve this issue by specifying data types and ensuring a consistent schema across all batches.
Please notice that we use Polars for data transformation and manipulation. Compared with Pandas, Polars offers better performance and scalability, making it a more cost-effective choice for production systems. This case study demonstrates that Polars can reduce computational costs, making it a good choice for projects that may eventually transition to production. Polars is a mature and robust library with extensive capabilities, making it an excellent choice for this project.
We can illustrate how the Mage flow operates using our first block. Initially, the block performs its main task—fetching data from an API in this example. The instructions for this task are defined in the block’s primary function, which is identified by the @data_loader decorator. Once the main task is completed, its output is passed to the tests, marked with the @test decorator. If all tests are successful, the output is forwarded to the next block in the stream.
When you first looked at Named figure 1, you might have wondered why storage spans the entire process and why Apache Arrow and Parquet are included in the storage block alongside DuckDB. This is because data storage underpins every major stage, with data being stored multiple times throughout its life cycle. Mage uses PyArrow to handle data serialization and deserialization between blocks during these storage steps7. For disk storage, PyArrow serializes the data into the Parquet format. For more details, you can check Mage’s documentation.
Below is an overview of how Mage blocks function:
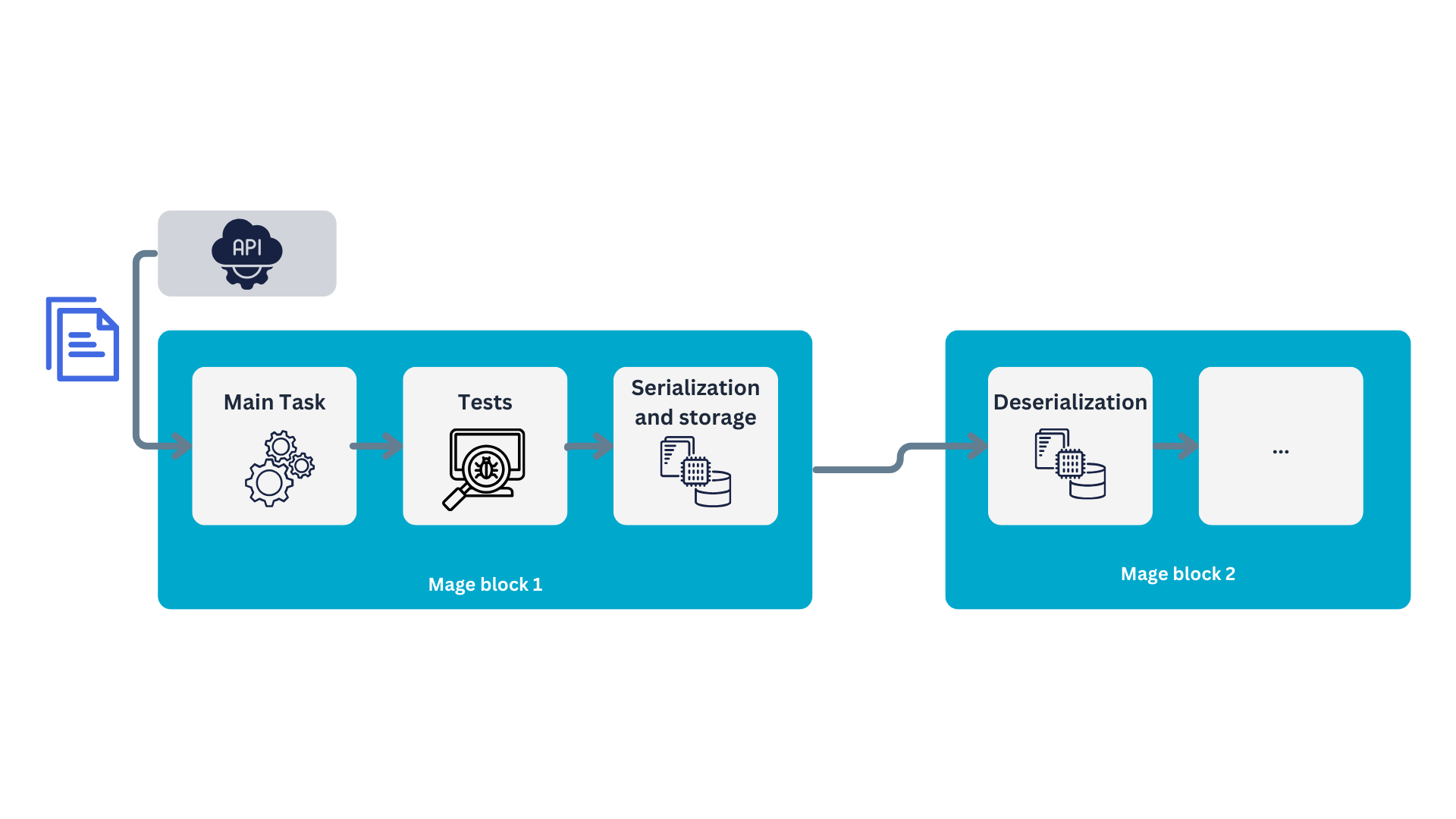
Congrats! You just implemented your first Mage block. Let’s test it, you can do this with the “play” icon in the header of the block:
After the block runs, you should be able to see the output in the tail of the block:
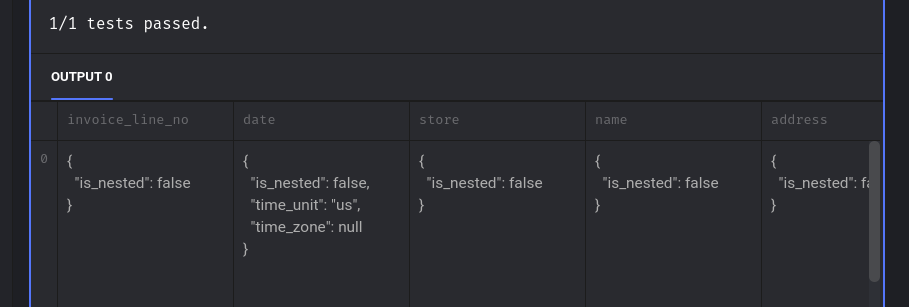
We see a message indicating that the test passed and how Mage tries to display the output dictionary.
Next, we will query the number of records (invoices) per year. To achieve this, we will create a data loader block named soda_records_per_year. The content of this block will look as follows:
Filename: data_loaders/soda_records_per_year.py
1import io
import polars as pl
import requests
if 'data_loader' not in globals():
from mage_ai.data_preparation.decorators import data_loader
if 'test' not in globals():
from mage_ai.data_preparation.decorators import test
2@data_loader
def load_data_from_api(*args, **kwargs):
# SoQL to get the the number of invoices per year
data_url = "https://data.iowa.gov/resource/m3tr-qhgy.csv?$select=date_extract_y(date) AS year, count(invoice_line_no) AS rows&$group=date_extract_y(date)"
print("\n")
print("Fetching the records-per-year metadata. This might take a couple minutes..")
response = requests.get(data_url)
print("Done! We have our year record metadata.\n")
data = pl.read_csv(io.StringIO(response.text))
return data
3@test
def test_output(output, *args) -> None:
assert output is not None, 'The output is undefined'
assert isinstance(output, pl.DataFrame), 'The output is not a Polars DataFrame'- 1
-
You might have noticed that we use the
iomodule to handle the API responses. Specifically, we utilize theStringIO()class to treat the response as a document. Otherwise, Polars will complain. - 2
- Here, we make a SoQL query to the API, and load the response into a Polars data frame.
- 3
- We also validate that the block’s output is not empty and confirm that it is a Polars data frame.
In this block we request the records per year to the API, for this we make use of the SoQL language provided by the API developers:
https://data.iowa.gov/resource/m3tr-qhgy.csv?$select=date_extract_y(date) AS year, count(invoice_line_no) AS rows&$group=date_extract_y(date)
And again, we can dissect this request:
- Teal: endpoint.
- Blue: query.
If we translate this query to SQL, we would have something like this:
SELECT YEAR(date) AS year
COUNT(invoice_line_no) AS rows
FROM m3tr-qhgy -- Iowa Liquor Sales table
GROUP BY YEAR(date)The output should be a table displaying the number of records for each year. This information will be used to determine the $limit clause when retrieving data later.
To complete the upstream blocks, we will create another block to check the data available in our local DuckDB database. I named this block check_local_db. It is of type “custom,” though it could also have been implemented as a data loader.
Filename: custom/check_local_db.py
# -- snip --
1db_path = 'data/iowa_liquor.duckdb'
@custom
def check_last_year(*args, **kwargs):
2 conn = duckdb.connect("data/iowa_liquor.duckdb")
3 try:
result = conn.execute("""
SELECT EXTRACT(YEAR FROM MAX(date)) FROM iowa_liquor_sales
""").fetchall()
last_year = result[0][0]
4 except duckdb.CatalogException as e:
print("The table doesn't exist; assigning rows_in_db=0")
last_year = 0
5 except Exception as e:
print(f"An unexpected error occurred: {e}")
last_year = 0
# Close DB connections
6 conn.close()
7 return last_year
# -- snip --- 1
-
Define the path to the database. For this project, the database will be stored in the file
data/iowa_liquor.duckdb. - 2
-
Establish a connection to the local database. If the file
iowa_liquor.duckdbdoes not exist, DuckDB will automatically create it. - 3
-
Query the date of the most recent invoice in the database and extract the year. Use
.fetchall()to retrieve the query output as a Python object8. - 4
-
If the table does not yet exist in the database, return
0as the year. - 5
-
If any other exception occurs, also return
0as the year. - 6
- Explicitly close the database connection to avoid blocking access for downstream processes.
- 7
-
Return the most recent year as an
int.
This block is designed to monitor the local database, enabling efficient updates by avoiding the need to fetch all data every time. This approach ensures faster processing and reduces resource consumption.
With that, we’ve completed the first layer of Mage blocks. The next step downstream involves retrieving the data of interest. In this stage, we will use the outputs of the three blocks we just created
Pulling the Iowa Liquor Sales data
With the metadata in place, we can now retrieve the sales data of interest by creating the pull_data_from_socrata block. Once this loader block is created, connect the upstream blocks to it in the following order:
get_schema_from_metadatasoda_records_per_yearcheck_local_db
You can make this configuration in the “Tree” panel to the right of your Mage code editor:
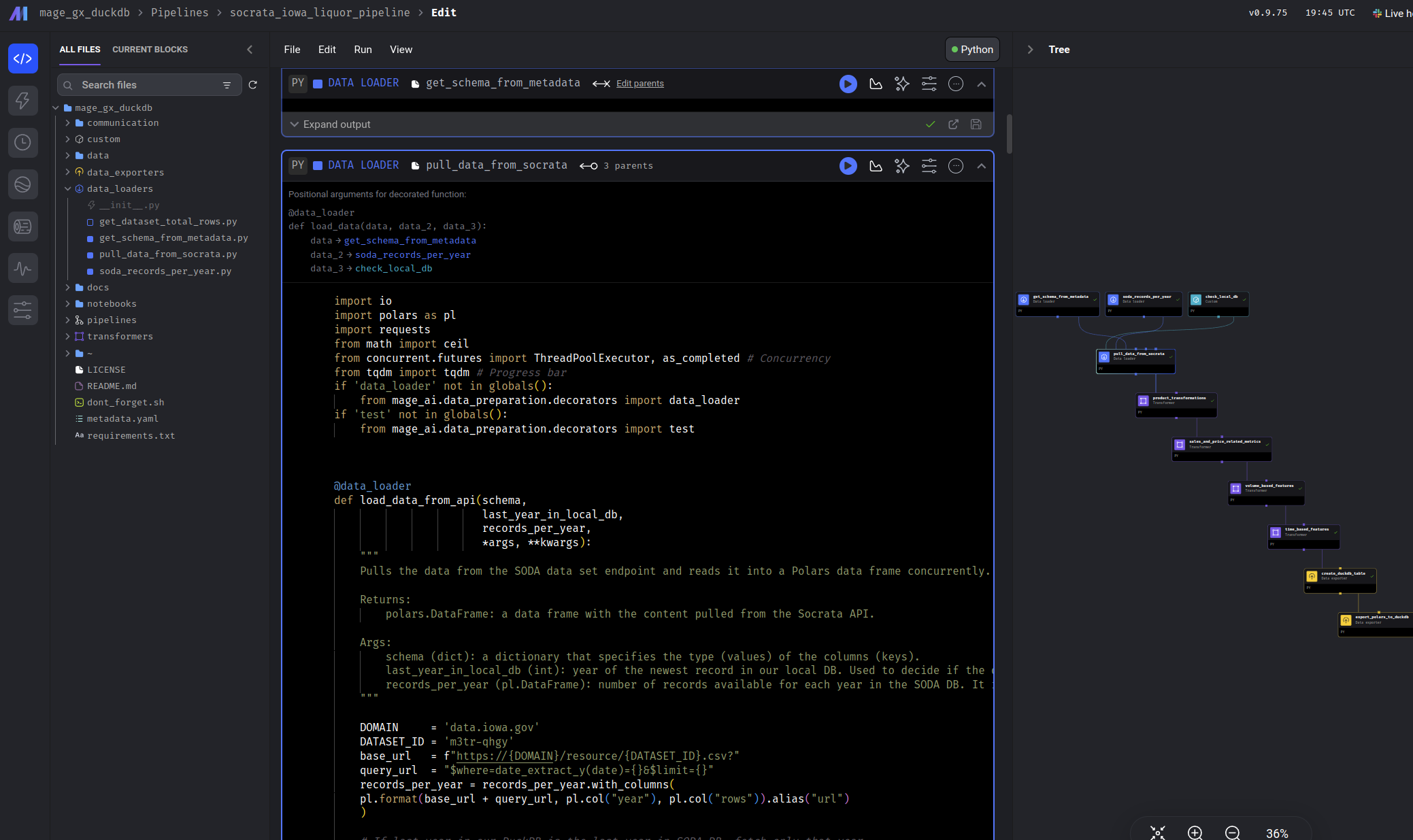
The final configuration should look like this:
This will ensure the parameter order remains consistent for you as well. While we know this block will utilize data from the three upstream blocks, how do we access this data in our code? The answer lies in the header of our new block, which contains all the information we need:
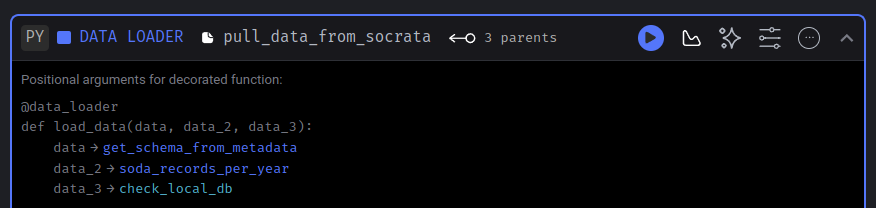
In this header, we receive all the necessary information to consume the upstream data. It includes an example showing the parameter order and how they correspond to each upstream block. The loader function, identified by the @data_loader decorator, provides a clear structure.
The parameter names (data, data_2, data_3) are arbitrary, allowing you to choose names that best suit your function. However, what matters most is the positional order of the parameters. Specifically:
- The first parameter corresponds to the output of
get_schema_from_metadata. - The second parameter corresponds to
soda_records_per_year. - The third parameter corresponds to
check_local_db.
With this in mind, we can proceed to define the content of this block. Since there is a lot to cover, we’ll break it down into three sections: the imports, the loader function, and the tests. Let’s start with the dependencies for this block:
Filename: data_loaders/pull_data_from_socrata.py
- 1
- Round numbers to the nearest ceiling.
- 2
- We will implement a multithreading approach to speed up the data retrieval process.
- 3
- A progress bar. Provides real-time feedback on the data-pulling progress, which besides of being helpful for the user, it’s also supportive for debugging purposes.
Nothing weird in the imports. Now, let’s review the most complex part of our implementation, the loader function:
Filename: data_loaders/pull_data_from_socrata.py
# -- snip --
@data_loader
1def load_data_from_api(schema,
records_per_year,
last_year_in_local_db,
*args, **kwargs):
2 DOMAIN = 'data.iowa.gov'
DATASET_ID = 'm3tr-qhgy'
base_url = f"https://{DOMAIN}/resource/{DATASET_ID}.csv?"
query_url = "$where=date_extract_y(date)={}&$limit={}"
records_per_year = records_per_year.with_columns(
pl.format(base_url + query_url, pl.col("year"), pl.col("rows")).alias("url")
)
3 records_per_year = records_per_year.filter(pl.col("year") >= last_year_in_local_db)
if (last_year_in_local_db != records_per_year["year"].max()) & last_year_in_local_db != 0:
# We're limiting to five years per job so our machine dont explode
records_per_year = records_per_year.sort("year").head(6)
records_per_year = records_per_year.filter(pl.col("year") != last_year_in_local_db)
# We're limiting to five years per job so our machine dont explode
4 records_per_year = records_per_year.sort("year").head(5)
# Years we will request to the API
5 requests_list = records_per_year["url"].to_list()
print("SODA data pull started.")
# Report to the user which years we will be working with
years_to_fetch = records_per_year["year"].to_list()
print("Years to be fetched: {}.".format(", ".join(map(str, years_to_fetch))))
# -- snip --- 1
- Parameter order: remember, the order of the parameters matters, but you can name them however you like.
- 2
-
Customizing API requests: The
records_per_yeardata frame is used to construct the URLs for API requests. It customizes the SoQL query for each year, with a unique$limitvalue tailored to the data volume for that year. - 3
- Excluding existing data: an additional filter ensures that years already present in the local database are excluded from the requests.
- 4
- Data pull limit: to prevent overloading your machine, we limit data pulls to a maximum of five years per run. Adjust this limit based on your system’s capacity.
- 5
- URL list: after filtering, the formatted URLs are collected into a list, which will be used later for parallel data fetching.
Up to this point, the process has been straightforward. We simply used some upstream data (records_per_year) to format the URLs needed for API requests, applying a few Polars transformations for text formatting. Lets continue reviewing the concurrent fetch of the data.
Filename: data_loaders/pull_data_from_socrata.py
# -- snip --
@data_loader
def load_data_from_api(schema,
records_per_year,
last_year_in_local_db,
*args, **kwargs):
# -- snip --
1 def fetch_batch(data_url):
"""Fetch data for a given URL."""
try:
response = requests.get(data_url)
response.raise_for_status() # Raise an error for bad responses
return pl.read_csv(io.StringIO(response.text), schema = schema)
except Exception as e:
print(f"Error fetching data from {data_url}: {e}")
return pl.DataFrame(schema = schema)
# Use ThreadPoolExecutor for concurrent API calls
df_list = []
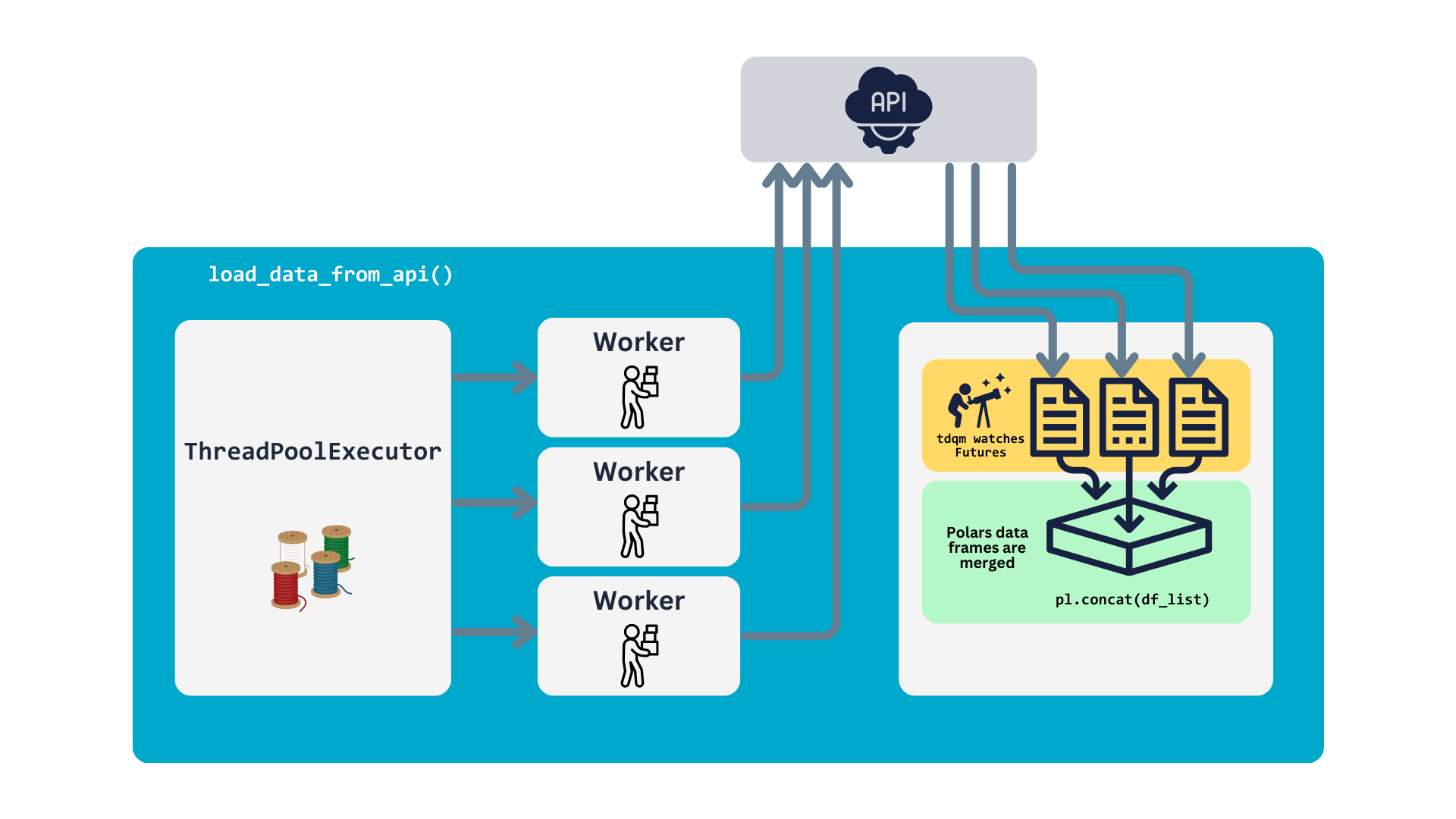
2 with ThreadPoolExecutor(max_workers = 3) as executor:
3 futures = {executor.submit(fetch_batch, url): url for url in requests_list}
4 for future in tqdm(as_completed(futures), total=len(futures), desc="Fetching data"):
url = futures[future]
try:
5 data = future.result()
if not data.is_empty():
df_list.append(data)
except Exception as e:
print(f"Error processing URL {url}: {e}")
6 all_pulled_data = pl.concat(df_list, how="vertical")
7 return all_pulled_data- 1
-
First we have to define a function that will handle the requests. It receives an URL, makes the
GETrequest, and returns a Polars data frame with the data. In case there is an error in our request, it also handles that. - 2
-
Initializes a thread pool with a maximum of three workers (
max_workers = 3), allowing up to three API requests to be executed concurrently. This will help to speed up the data retrieval. Thewithstatement is used for context management, ensuring the thread pool is properly shut down once all threads have completed their work. - 3
-
Here, we submit tasks to the thread pool. A dictionary is created using comprehension. The
executor.submit(...)method schedules thefetch_batchfunction to run in a separate thread withurlas its argument, returning aFutureobject. The resultingfuturesdictionary maps these Future objects to their corresponding URLs. - 4
-
To monitor progress, the code iterates over the
Futureobjects as they complete (usingas_completed) and tracks progress withtqdm, providing real-time feedback to the user. - 5
-
Retrieves the results, for each completed task,
future.result()is called to retrieve the result of thefetch_batchfunction. This method waits for the task to finish and returns the resulting Polars data frame. - 6
- All data frames are merged into a single one.
- 7
- Finally, the merged data frame containing all the requested data is returned.
So, this function utilizes ThreadPoolExecutor to submit API requests for all the URLs in requests_list. Tasks are executed in parallel based on the number of workers specified. Progress is monitored using tqdm, which updates the progress bar in real-time. The result (a Polars data frame) is retrieved and validated for each completed task. Once all tasks are complete, the individual data frames are merged into a single one, which is then returned. The process is illustrated in the following chart.
Testing
With the main functionality complete, ensuring that the loader runs reliably is essential, and equally important, to run automatic tests after making adjustments to the code9. To achieve this, we write tests to verify its behavior. Additionally, to maintain the best data quality in our pipeline, these tests also focus on ensuring the integrity and consistency of the data.
Let’s review the final part of our block, which consists of three tests. These tests are designed to validate certain expectations of the data, such as ensuring no null values in specific columns, and to verify the overall integrity of the data.
Filename: data_loaders/pull_data_from_socrata.py
# -- snip --
1@test
def test_output(output, *args) -> None:
"""
Validates the output of data pulling block.
"""
assert output is not None, 'The output is undefined'
assert isinstance(output, pl.DataFrame), "The output is not a Polars data frame"
assert len(output) > 0, "The data frame is empty"
2@test
def test_invoice_line_no_not_null_output(output, *args) -> None:
"""
Test the new invoice_line_no column contains no nulls.
"""
assert output["invoice_line_no"].is_null().sum() == 0, "The invoice_line_no column contains null values, it shouldn't"
3@test
def test_date_not_null_output(output, *args) -> None:
"""
Test the new date column contains no nulls.
"""
assert output["date"].is_null().sum() == 0, "The date column contain null values, it shouldn't"- 1
- Verify that the output is a non-empty Polars data frame containing valid content.
- 2
-
Ensure that the
invoice_line_nocolumn contains no null values. - 3
-
Confirm that the
datecolumn contains no null values.
When writing tests for your blocks, always include the @test decorator. This informs Mage to treat the functions as tests. In these examples, we verified the basic integrity of the resulting data frame and enforced specific rules for two columns. If everything went smoothly, you should see a confirmation message for each test that passed after running the block.
And we just finished implementing the data ingestion part of our pipeline! :D
Transform the data
With the retrieved data in hand, we now focus on transforming it. As illustrated in Named figure 2, after fetching the data and running the tests, the block serializes the data to pass it downstream. The next step is to implement these downstream blocks to transform the data and generate new variables.
Have present the bussiness logic
The dataset offers a wealth of information, such as product descriptions and geolocation points, providing ample opportunities for deeper insights and analysis. To enhance this further, we will create new variables that reveal additional business insights, enabling us to answer more interesting questions. We’ve organized the transformations into the following business-logic blocks:
product_transformations: generates general product descriptions, such as liquor type or packaging size.sales_and_price_related_metrics: creates variables like profits and costs.volume_based_features: develops features related to the liquid volume (Liters) of sales.time_based_features: generates temporal variables for time-based analysis.
Let’s transform our data
Most of the code in these blocks will be Polars transformations. If you are familiar with PySpark you will find that the syntax is similar, no worries if this is your first time with Polars, let’s review what the code does.
Filename: transformers/product_transformations.py
# -- snip --
@transformer
def transform(data, *args, **kwargs):
data = data.with_columns(
# Categorize liquors
1 pl.when(pl.col("category_name").str.contains("VODK")).then("Vodka")
.when(pl.col("category_name").str.contains("WHISK")).then("Whisky")
.when(pl.col("category_name").str.contains("RUM")).then("Rum")
.when(pl.col("category_name").str.contains("SCHN")).then("Schnapps")
.when(pl.col("category_name").str.contains("TEQ")).then("Tequila")
.when(
pl.col("category_name").str.contains("BRANDIE")
| pl.col("category_name").str.contains("BRANDY")
).then("Brandy")
.when(pl.col("category_name").str.contains("GIN")).then("Gin")
.when(pl.col("category_name").str.contains("MEZC")).then("Mezcal")
.when(
pl.col("category_name").str.contains("CREM")
| pl.col("category_name").str.contains("CREAM")
).then("Cream")
.otherwise("Other")
.alias("liquor_type"),
# Is premium
2 (pl.col("state_bottle_retail") >= 30).alias("is_premium"),
# Bottle size category
3 pl.when(pl.col("bottle_volume_ml") < 500).then("small")
.when((pl.col("bottle_volume_ml") >= 500) & (pl.col("bottle_volume_ml") < 1000)).then("medium")
.otherwise("large")
.alias("bottle_size")
)
print("Product-related new variables, generated.")
return data
# -- snip --- 1
- Categorize the liquor type (Tequila, Whisky, etc.).
- 2
- Determine whether the product is considered premium based on its individual price.
- 3
- Classify the product by size.
In this context, data represents the upstream DataFrame passed to this block by pull_data_from_socrata. It is the first parameter of the transform transformer. The Polars transformation begins with the with_columns method, which is used to add or replace columns in the DataFrame.
Within with_columns, we define the transformations. To create the first new variable, we use the pl.when() function to start a conditional statement. To reference a column, we use the pl.col() function. If you are only familiar with Pandas or dplyr, this might feel counterintuitive at first, but it works in a similar fashion—just pass the column name as a string, e.g., pl.col("your_col").
Once the column is selected, we apply the .str.contains() method to check if the string in a cell contains a specified pattern. If the pattern matches, the value specified in .then() will be used. We can chain additional .when() statements for more conditions, and the default value, used when no condition is met, is specified with .otherwise("Other"). To name the new column, we use .alias("liquor_type"). If the name matches an existing column, it will overwrite that column.
This transformation leverages chained operations, a powerful feature in Polars. Most Polars methods return a DataFrame, allowing you to immediately chain additional methods. This enhances code readability and makes debugging easier. Note that after the .alias() method, there is a comma , instead of a dot ., indicating the end of the chain.
Next, we proceed with premium and size categorizations in a similar manner.
Test, test, test!
Once the new variables are created, we will write tests for the outputs to ensure a baseline level of quality for the new data.
Filename: transformers/product_transformations.py
# -- snip --
1@test
def test_output(output, *args) -> None:
assert output is not None, 'The output is undefined'
2@test
def test_liquor_type_col(output, *args) -> None:
assert output.get_column("liquor_type") is not None, 'The column liquor_type is undefined'
assert output.get_column("liquor_type").dtype is pl.Utf8, "The new variable type doesn't match"
3@test
def test_is_premium_col(output, *args) -> None:
assert output.get_column("is_premium") is not None, 'The column is_premium is undefined'
assert output.get_column("is_premium").dtype is pl.Boolean, "The new variable type doesn't match"
4@test
def test_bottle_size_col(output, *args) -> None:
assert output.get_column("bottle_size") is not None, 'The column bottle_size is undefined'
assert output.get_column("bottle_size").dtype is pl.Utf8, "The new variable type doesn't match"- 1
- Validate the overall output has content.
- 2
-
Verify the
liquor_typecolumn’s content and data type. - 3
-
Check the
is_premiumcolumn’s content and data type. - 4
-
Ensure the
bottle_sizecolumn’s content and data type are correct.
Notice that each new variable has at least one associated test. While more detailed tests can be added later, these initial ones will suffice for now. And that’s essentially how a transformation block is structured. The next three transformation blocks follow a similar pattern, so I won’t explain them in detail, but feel free to review them as needed.
That concludes our data transformation step! Next, we’ll move on to storing our valuable data.
![]()
Persistent storage and serving
With a robust method for retrieving and transforming our data, the next step is to store and query it efficiently. For this purpose, we’ll use DuckDB. But why choose DuckDB?
DuckDB is well-known for its in-memory data manipulation capabilities, but it also supports persistent storage with several compelling advantages. By using DuckDB’s native storage format, we gain the following benefits:
- Free and open source: DuckDB is free and open-source, aligning with our preference for accessible and transparent tools10.
- Lightweight compression: it employs advanced compression techniques to reduce storage space while maintaining efficiency.
- Columnar vectorized query execution: DuckDB processes data in chunks (vectors) rather than row-by-row, making efficient use of CPU and memory. This design is optimized for modern hardware architectures. For a comprehensive explanation, see Kersten et al. (2018).
- Compact file structure: DuckDB stores data in a compact, self-contained binary file, making it portable and easy to manage.
- Comprehensible resources: besides excellent documentation, DuckDB has a fantastic community that makes it easy to use this database system. You can get a free copy of “DuckDB in Action” by Needham et al. (2024) on the MotherDuck webpage11.
Due to this and its ease of use12, DuckDB is an ideal tool for our purpose. So let’s continue with the implementation of our storage step.
After we have finished with our data transformers, we can move to the data exporters. Here, we could have done this by creating only one data exporter, but for the sake of keep the blocks simple and modular (only one task per block) I decided to create two blocks for the data exportation, one for creating the table we will use to store our data, and a last one to export the data. We will start by analyzing the block responsible of the table creation.
Filename: data_exporters/create_duckdb_table.py
- 1
-
We will use the
osmodule in our tests. - 2
- Python DuckDB client.
We start with the imports—of course, we’ll need the DuckDB client. If you’ve been following this tutorial, you should have installed it along with the dependencies. Next, we define a query to create the table where we will store our data. This step is crucial to specify the data types for each column.
Another critical aspect is defining constraints for the table. Here, we specify that two columns cannot contain null values and designate invoice_line_no as the primary key. But is this necessary? If we aim to enforce data integrity and prevent duplication, the answer is yes.
Filename: data_exporters/create_duckdb_table.py
# -- snip --
create_table_query = """
CREATE TABLE IF NOT EXISTS iowa_liquor_sales (
invoice_line_no TEXT PRIMARY KEY NOT NULL,
date TIMESTAMP NOT NULL,
store TEXT,
name TEXT,
address TEXT,
city TEXT,
zipcode TEXT,
store_location TEXT,
county_number TEXT,
county TEXT,
category TEXT,
category_name TEXT,
vendor_no TEXT,
vendor_name TEXT,
itemno TEXT,
im_desc TEXT,
pack REAL,
bottle_volume_ml REAL,
state_bottle_cost REAL,
state_bottle_retail REAL,
sale_bottles REAL,
sale_dollars REAL,
sale_liters REAL,
sale_gallons REAL,
liquor_type TEXT,
is_premium BOOLEAN,
bottle_size TEXT,
gov_profit_margin REAL,
gov_retail_markup_percentage REAL,
price_per_liter REAL,
price_per_gallon REAL,
total_volume_ordered_L REAL,
volume_to_revenue_ratio REAL,
week_day INTEGER,
is_weekend BOOLEAN,
quarter INTEGER
);
"""
# -- snip --This query also helps eliminate potential ambiguities when the data is exported. With the query defined, we can now move on to the main functionality of this block, the exporter13. The logic is quite simple.
Filename: data_exporters/create_duckdb_table.py
- 1
-
Create a connection to a file called
data/iowa_liquor.duckdb. If the file doesn’t exist it should create it - 2
- Creates the table with our query.
- 3
- Explicitly close the connection so no access to the database is blocked downstream
- 4
- Return the unmodified data that was passed upstream.
Here, we connect to our local database, create the table if it doesn’t exist, and close the connection to avoid blocking its access downstream. And that’s the main task of this block. Then, we validate that untouched upstream data has been passed and that the database file is also there:
Filename: data_exporters/create_duckdb_table.py
# -- snip --
@test
def test_output(output, *args) -> None:
assert output is not None, 'The output is undefined'
@test
def db_exist(*args) -> None:
assert os.path.exists("data/iowa_liquor.duckdb"), "The database file doesnt exist"Now we move to the real exporter, and the last block of our flow. And as you already guessed, here is where we store the retrieved data to our local database. First we establish a connection with our database, and use the object conn to interact with it, then we try to insert the freshly fetched and transformed data to the table iowa_liquor_sales. If a constraint exception is raised we check for duplicates in our batch, exclude them, and try to insert them again. This exception handling will be specially useful when we are at the stage of just updating with the last records our data base. You can examine this in the block:
Filename: data_exporters/export_polars_to_duckdb.py
# -- snip --
@data_exporter
def insert_data_in_table(data, *args, **kwargs):
1 conn = duckdb.connect("data/iowa_liquor.duckdb")
2 try:
conn.register("data", data)
conn.execute("INSERT INTO iowa_liquor_sales SELECT * FROM data")
3 except duckdb.ConstraintException as e:
print(e)
4 existing_keys_df = conn.execute("SELECT invoice_line_no FROM iowa_liquor_sales").fetchdf()
existing_keys_series = pl.DataFrame(existing_keys_df)["invoice_line_no"]
filtered_data = data.filter(~data["invoice_line_no"].is_in(existing_keys_series))
5 if filtered_data.height > 0:
conn.register("filtered_data", filtered_data)
conn.execute("INSERT INTO iowa_liquor_sales SELECT * FROM filtered_data")
else:
print("No new records to insert.")
6 conn.close()
print("Data loaded to your DuckDB database!")- 1
- Connect to the local database.
- 2
-
Attempt to insert the data into the
iowa_liquor_salestable. - 3
- If a constraint exception occurs, it likely means the batch of data pulled contains records already present in the database. It should not be about null values since we have already validated that upstream.
- 4
- In case of an exception, query the invoice IDs from the local database and filter out the duplicate records from the incoming batch.
- 5
-
If the filtered
DataFramestill contains records, proceed with inserting them into the table. - 6
- Close the database connection to ensure safety and prevent potential issues.
We have finished the implementation of our pipeline! Congrats!
Test the pipeline in Mage
Now it’s time to see if it works. To do this, click on the three-dot icon in the upper-right corner of your last block (export_polars_to_duckdb).
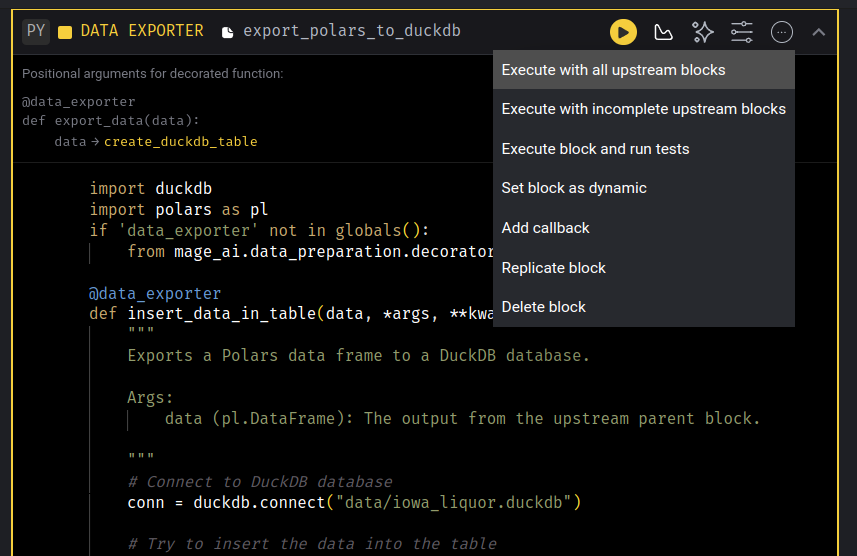
Here, select the option labeled “Execute with all upstream blocks.” This will run the entire pipeline. If an error occurs, Python/Mage will notify you, allowing you to begin debugging. If the process runs successfully, then your first batch of data will be stored in your local database.
Run the data pipeline in the terminal
Now open a terminal in the project folder and run:
uv run mage run . socrata_iowa_liquor_pipelineWe use uv run to execute the Mage command inside the project’s managed environment. The Mage run command executes the pipeline. The dot (.) refers to the current directory (assuming you’re in the project’s folder), and socrata_iowa_liquor_pipeline is the name of our pipeline. If everything runs successfully, your second batch should now be stored in your local database. A successful output will look like this:
user@user-pc:~/mage_duckdb_pipeline$ uv run mage run . socrata_iowa_liquor_pipeline
Fetching the records-per-year metadata. This might take a couple minutes..
Done! We have our year record metadata.
SODA data pull started.
Years to be fetched: 2017, 2018, 2019, 2020, 2021.
Fetching data: 100%|█████████████████████████████████████| 5/5 [10:08<00:00, 121.69s/it]
Product-related new variables, generated.
Sales and price related metrics, computed.
Volume-based features, computed.
Time-based features, computed.
Data loaded to your DuckDB database!
Pipeline run completed.You can continue with this until your local data is up to date. Remember that we set a limit to fetch a maximum of five years per run. Feel free to adjust this in the pull_data_from_socrata loader.
Should I manually run the pipeline whenever I need to update the data?
Running the pipeline in your terminal might be an option, but not the most appealing one, depending on your use case. For instance, the Iowa Liquor data set is updated once per month with the new data available on the 1st of each month, according to its documentation. Therefore, it makes sense to run an update job once per month. We can configure a trigger for this, and it is very easy to do, so go review Mage’s documentation if you are in the need.
And our data is ready to be served via SQL! We can continue with the pipeline’s end goal: analytics and predictive modeling.
Data analytics
Many proprietary dashboarding tools can take advantage of our DuckDB database. But in keeping with the spirit of our project, we will use the R language for this purpose since it is free, open-source14, and extremely powerful.
We start by connecting to our local database within our R environment. This connection will be called conn:
conn <- DBI::dbConnect(
drv = duckdb::duckdb(),
dbdir = "../data/iowa_liquor.duckdb",
read_only = TRUE
)Notice that we indicate read_only = TRUE so this connection can be shared between processes. With our connection in place, let’s query some data to visualize:
SELECT
date,
liquor_type,
SUM(sale_bottles) AS bottles_sold
FROM iowa_liquor_sales
GROUP BY date, liquor_typeThe output table of this query is stored in the object bottles_sold_per_type. Let’s have a peek at it:
bottles_sold_per_type %>%
head(5) %>%
gt::gt()| date | liquor_type | bottles_sold |
|---|---|---|
| 2012-02-27 | Vodka | 21013 |
| 2012-06-18 | Vodka | 25394 |
| 2012-09-13 | Vodka | 31004 |
| 2012-07-02 | Vodka | 28536 |
| 2012-10-09 | Whisky | 36500 |
Let’s say we want to know how well we sell liquor and see if there is a trend in our historical data. We start by aggregating our freshly queried data. One advantage of using R is that its libraries have pretty useful abstractions; for example, we will use floor_date from lubridate to aggregate the data by month.
bottle_sales_by_month <- bottles_sold_per_type %>%
group_by(month = floor_date(date, 'month'), # Group by month
liquor_type) %>%
summarise(monthly_bottles_sold = sum(bottles_sold))Using lubridate is more straightforward and less verbose than applying this logic in SQL, so we took advantage of R capabilities. Now that our data is ready let’s visualize it to get some knowledge:
month_sales_plot <- ggplot(bottle_sales_by_month, aes(x = month, y = monthly_bottles_sold, color = liquor_type)) +
geom_line() +
geom_point() +
labs(
title = "Liquor bottles sold by month",
x = "Date",
y = "Bottles sold",
color = "Liquor type"
) +
theme_minimal() +
theme(
plot.title = element_text(hjust = 0.5)
)
plotly::ggplotly(month_sales_plot)Since this chart is interactive, you can zoom in to examine it further; to zoom out, double-click on the chart.
The most popular liquors in Iowa seem to be whisky and vodka. The good news for Mezcal adepts is that it has been available in stores since 2016. Let’s say we like mezcal and want to buy a bottle as a treat. However, as the chart shows, it is not the most popular drink, so now we want to know where to buy a bottle. Our quest will begin with a query to our DuckDB.
For this query, we will use a Common Table Expression (CTE) to retrieve the latest record for each store. We also filter the data to include only records from 2024 onward, where a geolocation is available, and the invoice corresponds to a mezcal purchase. Since the CTE ranks records by the most recent purchases, we can easily select the first record for each store in the main query.
WITH ranked_stores AS (
SELECT
store,
name,
address,
store_location,
ROW_NUMBER() OVER (PARTITION BY store ORDER BY date DESC) AS row_num
FROM iowa_liquor_sales
WHERE YEAR(date) >= 2024
AND YEAR(date) <= 2025
AND store_location IS NOT NULL
AND liquor_type = 'Mezcal'
)
SELECT store, name, address, store_location
FROM ranked_stores
WHERE row_num = 1;The resulting table is stored in bottles_sold_per_type, let’s examine it:
bottles_sold_per_type %>%
head(3) %>%
gt::gt()| store | name | address | store_location |
|---|---|---|---|
| 010028 | DUAL STOP CARTER LAKE / CARTER LAKE | 109 EAST LOCUST STREET | POINT (-95.928949982 41.284808987) |
| 4070 | GRIEDER BEVERAGE DEPOT | 708 13TH ST | POINT (-92.277218966 41.897301014) |
| 010335 | DISCOUNT LIQUOR TOBACCO & VAPE / CRESTON | 509 WEST TAYLOR STREET SUITE B | POINT (-94.367469984 41.049663998) |
It contains the:
- Store code (ID)
- Store address
- Store name
- Geolocation
All the information we need to get our bottle. But a table with more than 300 stores is not easy to digest. So let’s put that into a map; locating the stores closest to us would be easy.
We will begin by converting our retrieved information into a simple features object (sf). The sf library greatly simplifies geospatial analysis, especially when working with geometry data types. First, we transform the store_location column (which is string type) into a POINT geometry type using the st_as_sfc function. Specifying the coordinate reference system (crs = 4326) is crucial here.
Although our dataset documentation does not explicitly mention the coordinate reference system, WGS84 CRS (EPSG:4326) is the most logical choice. This is because WGS84 is the standard and most widely used system for representing latitude-longitude coordinates, making it the most likely CRS for our data15. Please check Lovelace, Nowosad, and Muenchow (2025) to learn more about simple features and geospatial analysis. I was introduced to sf in the first edition and learned a lot; this second one is pure fire!
bottles_sold_per_type_0 <- bottles_sold_per_type %>%
mutate(geometry = st_as_sfc(store_location, crs = 4326)) %>%
select(-store_location) %>%
st_as_sf()
# To peep the contents of our sf object
bottles_sold_per_type_0Simple feature collection with 454 features and 3 fields
Geometry type: POINT
Dimension: XY
Bounding box: xmin: -96.46188 ymin: 40.40001 xmax: -90.18479 ymax: 43.44374
Geodetic CRS: WGS 84
First 10 features:
store name
1 010028 DUAL STOP CARTER LAKE / CARTER LAKE
2 4070 GRIEDER BEVERAGE DEPOT
3 010335 DISCOUNT LIQUOR TOBACCO & VAPE / CRESTON
4 4152 FOOD LAND SUPER MARKETS
5 6265 KC STORE / STRATFORD
6 010598 C'S LIQUOR / SPENCER
7 3990 CORK AND BOTTLE / OSKALOOSA
8 4201 FAREWAY STORES #022 / SIOUX CITY
9 3465 HOMETOWN FOODS / PANORA
10 4800 WALGREENS #07968 / DES MOINES
address geometry
1 109 EAST LOCUST STREET POINT (-95.92895 41.28481)
2 708 13TH ST POINT (-92.27722 41.8973)
3 509 WEST TAYLOR STREET SUITE B POINT (-94.36747 41.04966)
4 407 W HURON POINT (-95.89925 41.55798)
5 810 IA-175 POINT (-93.92732 42.2678)
6 719 2ND AVE W POINT (-95.14776 43.14541)
7 309 A AVE WEST POINT (-92.64815 41.29623)
8 4040 WAR EAGLE DR POINT (-96.46188 42.49426)
9 601 E MAIN POINT (-94.35746 41.69241)
10 6200 SE 14TH ST POINT (-93.59785 41.52875)We displayed a print of the contents of our sf object so you can get a sense of what it is: a data frame with geospatial metadata and geometry types. DuckDB has some extensions that make geospatial types available, but we are not using them here to avoid adding more complexity to the upstream system.
Let’s continue with our map. We will create the map using the leaflet library; it is easy to use and has beautiful and usable results. We feed this visualization with the sf object we just created.
leaflet(data = bottles_sold_per_type_0) %>%
addProviderTiles(providers$CartoDB.Positron) %>% # Add a base map
addCircleMarkers(
lng = ~st_coordinates(geometry)[, 1], # Extract longitude
lat = ~st_coordinates(geometry)[, 2], # Extract latitude
popup = ~paste0(
"<strong>Store:</strong> ", name, "<br>",
"<strong>Address:</strong> ", address, "<br>"
),
radius = 5,
color = "#ed7c65",
fillOpacity = 0.7
) %>%
addLegend(
position = "bottomright",
title = "Liquor stores that sell mezcal in Iowa",
colors = "#ed7c65",
labels = "Store locations",
opacity = 0.7
)Great! Now, we have an interactive map of the stores that recently ordered mezcal. We can look for the closest one and go there for our treat. You can also click the dot of your store of interest to get its name and address.

Now that we better understand our data, we can use our DuckDB to feed some algorithms and get predictive (machine learning) models.
Predictive modeling (machine learning)
We have a lightning-fast local database for advanced analytics, and we can use the same resource for statistical and predictive modeling. Let’s say some gangster is dissin ya’ fly girl we’re at the start of 2025, and the supply chain team is interested in rum supply for the upcoming 2025 and 2026 period due to the holidays.

You don’t know the details well, but you suspect it has something to do with a conversation you overheard about Martha Stewart’s jet fuel recipe getting too popular. Anyways, you’re excited since you were looking forward to doing some forecasting work by now.
You start by setting up your Python environment for this job. R is undoubtedly nice for advanced analytics, but you do your machine learning with Python16. In this example, we will use skforecast, a library that adapts scikit-learn compatible estimators to time series forecasting tasks. The idea is to transform the time series into a supervised learning problem using lagged values as predictors, then use a standard regression model to generate recursive multi-step forecasts.
import duckdb
import numpy as np
import pandas as pd
from skforecast.recursive import ForecasterRecursive
from sklearn.ensemble import HistGradientBoostingRegressorWith your prelude ready, we continue by establishing a connection with our local database:
conn_py = duckdb.connect("../data/iowa_liquor.duckdb", read_only=True)After we have created a connection in Python, we can query the data we need for the model. A subtle but important detail: if we are forecasting from the start of 2025, we should not use sales from 2025 or 2026 as input features. That information would not exist yet when the forecast is made. For this reason, we will make a small but valid forecasting example using only the historical rum series, lagged sales values created by skforecast, and calendar features that are known in advance, such as the month of the year.
query_rum_sales = """
SELECT
CAST(DATE_TRUNC('month', date) AS DATE) AS year_month,
SUM(sale_bottles) AS bottles_sold
FROM iowa_liquor_sales
WHERE date < DATE '2027-01-01'
AND liquor_type = 'Rum'
GROUP BY year_month
ORDER BY year_month;
1"""
2rum_sales = conn_py.sql(query_rum_sales).df()
3rum_sales.head(5)- 1
-
Build the SQL query that aggregates bottle sales to one row per month for the
Rumcategory. - 2
- Execute the query with DuckDB and convert the result to a Pandas data frame for the modeling workflow.
- 3
- Preview the first rows before transforming the result into a regular time series.
year_month bottles_sold
0 2012-01-01 180254.0
1 2012-02-01 195347.0
2 2012-03-01 208190.0
3 2012-04-01 214784.0
4 2012-05-01 258237.0We write the query as a docstring and then pass it to the .sql() command. Also, notice that we get our query results as a Pandas data frame with the .df() at the end.
Since we are working with time series data, we will need to organize our data by month and split it chronologically. Remember that the order of our observations matters in this kind of data. Also we will split our data in two sets, one for training, another for testing.
1rum_sales['year_month'] = pd.to_datetime(rum_sales['year_month'])
rum_sales = (
rum_sales
.set_index('year_month')
2 .sort_index()
3 .asfreq('MS')
4 .fillna({'bottles_sold': 0})
.reset_index()
)
5forecast_start = pd.Timestamp('2025-01-01')
y = (
rum_sales
6 .set_index('year_month')['bottles_sold']
.astype(float)
.asfreq('MS')
.fillna(0)
)
7y_train = y[y.index < forecast_start]
y_test = y[y.index >= forecast_start]
8if y_test.empty:
raise ValueError(
"No observations were found from 2025 onward. "
"Run the pipeline with data that includes the 2025 and 2026 period."
)
9train_df = y_train.rename('bottles_sold').reset_index()
test_df = y_test.rename('bottles_sold').reset_index()
train_df.tail(3), test_df.head(3)- 1
- Convert the month column to a datetime type so Pandas can use time-aware indexing.
- 2
- Ensure the data is in chronological order before creating a time series.
- 3
- Force a regular monthly-start frequency, which is what the forecaster expects.
- 4
- Fill missing months with zero bottle sales so the series has no temporal gaps.
- 5
- Define the forecast period, which in this case starts in January 2025 and continues through the 2026 months available in the database.
- 6
- Extract the target series that the model will forecast.
- 7
- Split the data chronologically: everything before 2025 is training data, and everything from 2025 onward is the holdout set.
- 8
- Stop early if the local database does not contain a valid 2025 and 2026 evaluation period.
- 9
- Create small data frames for display so we can inspect the train/test boundary.
( year_month bottles_sold
153 2024-10-01 205951.0
154 2024-11-01 243080.0
155 2024-12-01 191137.0, year_month bottles_sold
0 2025-01-01 168174.0
1 2025-02-01 147554.0
2 2025-03-01 207732.0)With our disjoint sets ready, we can continue with the next step: creating calendar variables that are available at prediction time. skforecast will create the lag features internally, but we can still pass known future information as exogenous variables. Here, we add a trend and two cyclical month features. These are safe because, at the start of 2025, we already know which months belong to 2025 and 2026.
1def calendar_exog(dates, origin):
"""Create calendar features known before the forecast period begins."""
2 dates = pd.DatetimeIndex(pd.to_datetime(dates))
months_from_origin = (
(dates.year - origin.year) * 12 +
(dates.month - origin.month)
3 ).astype(float)
return pd.DataFrame(
{
4 'trend': months_from_origin,
5 'month_sin': np.sin(2 * np.pi * dates.month / 12),
'month_cos': np.cos(2 * np.pi * dates.month / 12),
},
index=dates,
)
6origin = y.index.min()
7exog = calendar_exog(y.index, origin=origin)
8exog_train = exog.loc[y_train.index]
exog_test = exog.loc[y_test.index]
exog_train.tail(3)- 1
- Wrap the feature engineering logic in a small function so we can reuse the same transformation for training and forecasting dates.
- 2
-
Convert the input dates into a
DatetimeIndex, which gives convenient access to year and month attributes. - 3
- Count how many months have passed since the first observation; this creates a simple trend feature.
- 4
- Include the trend as a feature known in advance for all future months.
- 5
- Encode seasonality with sine and cosine terms, which lets the model learn December and January as neighboring months rather than unrelated labels.
- 6
- Use the first observed month as the origin of the trend calculation.
- 7
- Build the exogenous feature table for the full time span.
- 8
- Align the exogenous features with the training and holdout indexes so the rows match the target series exactly.
trend month_sin month_cos
year_month
2024-10-01 153.0 -8.660254e-01 0.500000
2024-11-01 154.0 -5.000000e-01 0.866025
2024-12-01 155.0 -2.449294e-16 1.000000With the calendar features ready, we can train the model. We will model log1p(bottles_sold) instead of raw bottle counts. This keeps predictions positive after transforming the values back to the original scale and makes the residuals more stable.
1y_train_log = np.log1p(y_train)
2forecaster = ForecasterRecursive(
3 estimator=HistGradientBoostingRegressor(
loss='squared_error',
learning_rate=0.05,
max_iter=500,
max_leaf_nodes=8,
l2_regularization=0.1,
random_state=123,
),
4 lags=12,
)
5forecaster.fit(
y=y_train_log,
exog=exog_train,
6 store_in_sample_residuals=True,
)
7pd.DataFrame(
{
'component': [
'forecaster',
'estimator',
'lags',
'target scale',
'training period',
],
'value': [
'ForecasterRecursive',
'HistGradientBoostingRegressor',
'1 to 12 months',
'log1p(bottles_sold)',
f"{y_train.index.min().date()} to {y_train.index.max().date()}",
],
}
)- 1
-
Transform the target with
log1pso very large months have less influence and the inverse transformation remains valid for zero sales. - 2
- Create a recursive forecaster that will repeatedly predict one step ahead until it covers the full holdout period.
- 3
- Use a scikit-learn gradient boosting regressor as the underlying machine learning model.
- 4
- Give the model the previous 12 months as autoregressive predictors, which is a natural choice for monthly seasonal data.
- 5
- Fit the forecaster only on observations available before January 2025.
- 6
-
Store in-sample residuals so
skforecastcan later build a bootstrapped prediction interval. - 7
- Print a compact model summary to make the configuration explicit in the rendered tutorial.
component value
0 forecaster ForecasterRecursive
1 estimator HistGradientBoostingRegressor
2 lags 1 to 12 months
3 target scale log1p(bottles_sold)
4 training period 2012-01-01 to 2024-12-01First, skforecast turns the monthly series into a supervised learning table using the previous 12 months as predictors. Then, the gradient boosting model learns how those lagged values and calendar variables relate to the next monthly value. This is a stronger machine learning example than the earlier simple regression because the model is now learning from the recent behavior of the series itself, not only from a trend and month indicators.
We also set store_in_sample_residuals=True when fitting the forecaster. This stores the training residuals that skforecast needs later to build the bootstrapped prediction interval around the point forecast.
Once the model is set up, we train it using the historical data available before January 2025. With the trained model ready, we can proceed to forecasting. Now, let’s predict the rum sales:
1forecast_log = forecaster.predict_interval(
2 steps=len(y_test),
3 exog=exog_test,
4 method='bootstrapping',
5 interval=[5, 95],
6 n_boot=500,
7 use_in_sample_residuals=True,
use_binned_residuals=False,
random_state=123,
suppress_warnings=True,
)
# Keep the forecast index aligned with the observed holdout period.
8forecast_log.index = y_test.index
9forecast_results = pd.DataFrame(
{
'year_month': y_test.index,
'bottles_sold': y_test.to_numpy(),
10 'forecast': np.expm1(forecast_log['pred'].to_numpy()),
'lower': np.expm1(forecast_log['lower_bound'].to_numpy()),
'upper': np.expm1(forecast_log['upper_bound'].to_numpy()),
}
)
11for column in ['forecast', 'lower', 'upper']:
forecast_results[column] = np.clip(forecast_results[column], a_min=0, a_max=None)
12forecast_results['lower'] = np.minimum(
forecast_results['lower'],
forecast_results['forecast'],
)
forecast_results['upper'] = np.maximum(
forecast_results['upper'],
forecast_results['forecast'],
)
forecast_results- 1
- Generate both the point forecast and the interval in one call.
- 2
- Forecast exactly the number of months in the holdout period.
- 3
- Pass the future calendar features, which are known before the forecast period begins.
- 4
- Use bootstrapped residuals to simulate plausible forecast paths around the point prediction.
- 5
- Request the 5th and 95th percentiles, which produces a 90% interval.
- 6
- Use 500 bootstrap simulations to estimate the interval bounds.
- 7
- Use the residuals stored during training as the empirical error source.
- 8
- Align the forecast index with the actual 2025 and 2026 months so comparison and plotting are straightforward.
- 9
- Build one tidy table that combines the observed holdout values, point forecast, and interval bounds.
- 10
-
Transform predictions back from
log1pto the original bottle-count scale. - 11
- Clip negative values to zero because bottle counts cannot be negative.
- 12
- Ensure the lower and upper interval bounds are logically ordered around the point forecast.
year_month bottles_sold forecast lower upper
0 2025-01-01 168174.0 186701.638901 183187.599287 190542.099210
1 2025-02-01 147554.0 180378.979591 176849.665009 184276.595001
2 2025-03-01 207732.0 213916.401322 209730.893566 218498.804844
3 2025-04-01 184243.0 193726.061978 190079.811587 198223.585587
4 2025-05-01 194428.0 217359.758560 212452.428888 223855.086970
5 2025-06-01 205705.0 215618.342976 210488.253682 219702.120293
6 2025-07-01 197622.0 211968.497834 206454.850501 216121.052747
7 2025-08-01 173884.0 184186.843069 180760.188521 188792.080470
8 2025-09-01 168422.0 186314.703964 182890.036185 191578.398863
9 2025-10-01 177844.0 204862.927359 200705.196897 210349.424893
10 2025-11-01 222039.0 234052.408687 225504.507737 239139.367025
11 2025-12-01 193030.0 185490.906654 181337.700425 190733.788436
12 2026-01-01 153057.0 183946.965129 179475.626337 187370.527411
13 2026-02-01 147044.0 185970.594030 180725.889768 189883.593079
14 2026-03-01 225089.0 216700.501434 210728.198480 222226.834279
15 2026-04-01 163352.0 192603.841449 188234.809631 197698.956642Forecasted rum sales for the 2025 and 2026 months available in the database:
forecast_results[['year_month', 'forecast', 'lower', 'upper']] year_month forecast lower upper
0 2025-01-01 186701.638901 183187.599287 190542.099210
1 2025-02-01 180378.979591 176849.665009 184276.595001
2 2025-03-01 213916.401322 209730.893566 218498.804844
3 2025-04-01 193726.061978 190079.811587 198223.585587
4 2025-05-01 217359.758560 212452.428888 223855.086970
5 2025-06-01 215618.342976 210488.253682 219702.120293
6 2025-07-01 211968.497834 206454.850501 216121.052747
7 2025-08-01 184186.843069 180760.188521 188792.080470
8 2025-09-01 186314.703964 182890.036185 191578.398863
9 2025-10-01 204862.927359 200705.196897 210349.424893
10 2025-11-01 234052.408687 225504.507737 239139.367025
11 2025-12-01 185490.906654 181337.700425 190733.788436
12 2026-01-01 183946.965129 179475.626337 187370.527411
13 2026-02-01 185970.594030 180725.889768 189883.593079
14 2026-03-01 216700.501434 210728.198480 222226.834279
15 2026-04-01 192603.841449 188234.809631 197698.956642Here is the predicted output for the forecast period starting in 2025. Let’s evaluate the model to see how well it performed against the observed ground truth.
- 1
- Calculate forecast errors as observed sales minus forecasted sales for each holdout month.
- 2
- Compute MAE, which reports the average absolute error in bottles.
- 3
- Compute RMSE, which penalizes larger misses more strongly than MAE.
- 4
- Return the metrics in a small table for the rendered article.
metric value
0 MAE 18527.222298
1 RMSE 21112.609502These numbers don’t tell us much on their own, and it would be ideal to compare them against the MAE and RMSE of another model. However, we won’t invest more time in that. Feel free to train a different model to make the comparison!
Next, a key step in evaluating the model is visualizing how its forecasts compare with the observed ground truth. To achieve this, we create an interactive time series chart of our forecast. The chart separates the historical observations used for training from the holdout period, overlays the forecast, and adds a bootstrapped uncertainty band from skforecast:
plot_train <- reticulate::py_to_r(reticulate::py$plot_train) %>%
1 mutate(year_month = as.Date(year_month))
plot_holdout <- reticulate::py_to_r(reticulate::py$plot_holdout) %>%
2 mutate(year_month = as.Date(year_month))
plot_forecast <- reticulate::py_to_r(reticulate::py$plot_forecast) %>%
3 mutate(year_month = as.Date(year_month))
4forecast_start_plot <- as.Date(reticulate::py_to_r(reticulate::py$forecast_start_plot))
plotly::plot_ly() %>%
5 plotly::add_ribbons(
data = plot_forecast,
x = ~year_month,
ymin = ~lower,
ymax = ~upper,
name = "90% bootstrapped interval",
fillcolor = "rgba(31, 119, 180, 0.16)",
line = list(color = "rgba(31, 119, 180, 0)"),
hoverinfo = "skip"
) %>%
6 plotly::add_trace(
data = plot_train,
x = ~year_month,
y = ~bottles_sold,
type = "scatter",
mode = "lines+markers",
name = "Observed history",
line = list(color = "#37474F", width = 2),
marker = list(size = 6),
hovertemplate = "%{x|%b %Y}<br>Observed: %{y:,.0f} bottles<extra></extra>"
) %>%
7 plotly::add_trace(
data = plot_holdout,
x = ~year_month,
y = ~bottles_sold,
type = "scatter",
mode = "lines+markers",
name = "Observed holdout",
line = list(color = "#00897B", width = 2),
marker = list(size = 7),
hovertemplate = "%{x|%b %Y}<br>Observed: %{y:,.0f} bottles<extra></extra>"
) %>%
8 plotly::add_trace(
data = plot_forecast,
x = ~year_month,
y = ~forecast,
type = "scatter",
mode = "lines+markers",
name = "Forecasted rum sales",
line = list(color = "#D81B60", width = 3, dash = "dash"),
marker = list(size = 7),
hovertemplate = "%{x|%b %Y}<br>Forecast: %{y:,.0f} bottles<extra></extra>"
) %>%
9 plotly::layout(
title = list(
text = "Forecast of monthly rum bottles sold, 2025 to 2026",
x = 0
),
xaxis = list(
title = "Month",
10 rangeslider = list(visible = TRUE)
),
yaxis = list(
title = "Bottles sold",
tickformat = ",.0f"
),
11 hovermode = "x unified",
legend = list(
orientation = "h",
x = 0,
y = 1.08
),
margin = list(l = 60, r = 30, t = 90, b = 40),
12 shapes = list(
list(
type = "line",
x0 = forecast_start_plot,
x1 = forecast_start_plot,
y0 = 0,
y1 = 1,
xref = "x",
yref = "paper",
line = list(color = "#757575", dash = "dash")
)
),
13 annotations = list(
list(
x = forecast_start_plot,
y = 1,
xref = "x",
yref = "paper",
text = "Forecast starts",
showarrow = FALSE,
xanchor = "left",
yanchor = "bottom"
)
)
)- 1
-
Convert the training history from Python to R and make sure the month column is an R
Date. - 2
- Convert the observed holdout data, which represents the future months we are using for evaluation.
- 3
- Convert the forecast table, including the point forecast and the bootstrapped interval bounds.
- 4
- Convert the forecast start date so it can be reused in Plotly shapes and annotations.
- 5
- Draw the interval first so it appears behind the observed and forecasted lines.
- 6
- Add the historical training series.
- 7
- Add the observed holdout series, which is the ground truth for the forecast period.
- 8
- Add the model forecast as a dashed line so it is visually distinct from observed data.
- 9
- Configure the chart title, axes, legend, margins, and visual guides.
- 10
- Add a range slider so the reader can zoom into specific months interactively.
- 11
- Use unified hover so all values for the same month appear together.
- 12
- Draw a vertical reference line at January 2025, the beginning of the forecast period.
- 13
- Add a small label to make the split between history and forecast easy to interpret.
We can now compare the forecast with the ground truth for the 2025 and 2026 months that are already available in the database. Remember that, in real life, the ground truth would not be available when we make the forecast. The important modeling fix is that the forecast uses only information available before the forecast period begins, plus historical lag values and calendar information we already know. The uncertainty band comes from bootstrapped residuals, so it should be interpreted as a lightweight diagnostic interval rather than a formal business guarantee. So you can now go with your stakeholders and present this chart so they can organize their rum orders for the upcoming period.
That’s fantastic! But can we go even further downstream in our data flow by diving into stakeholder management, effective result presentation, and model monitoring? 🤩
Yes, but “what do we say to the god of death?”

And there you have it: we have used our DuckDB data to create a predictive model!
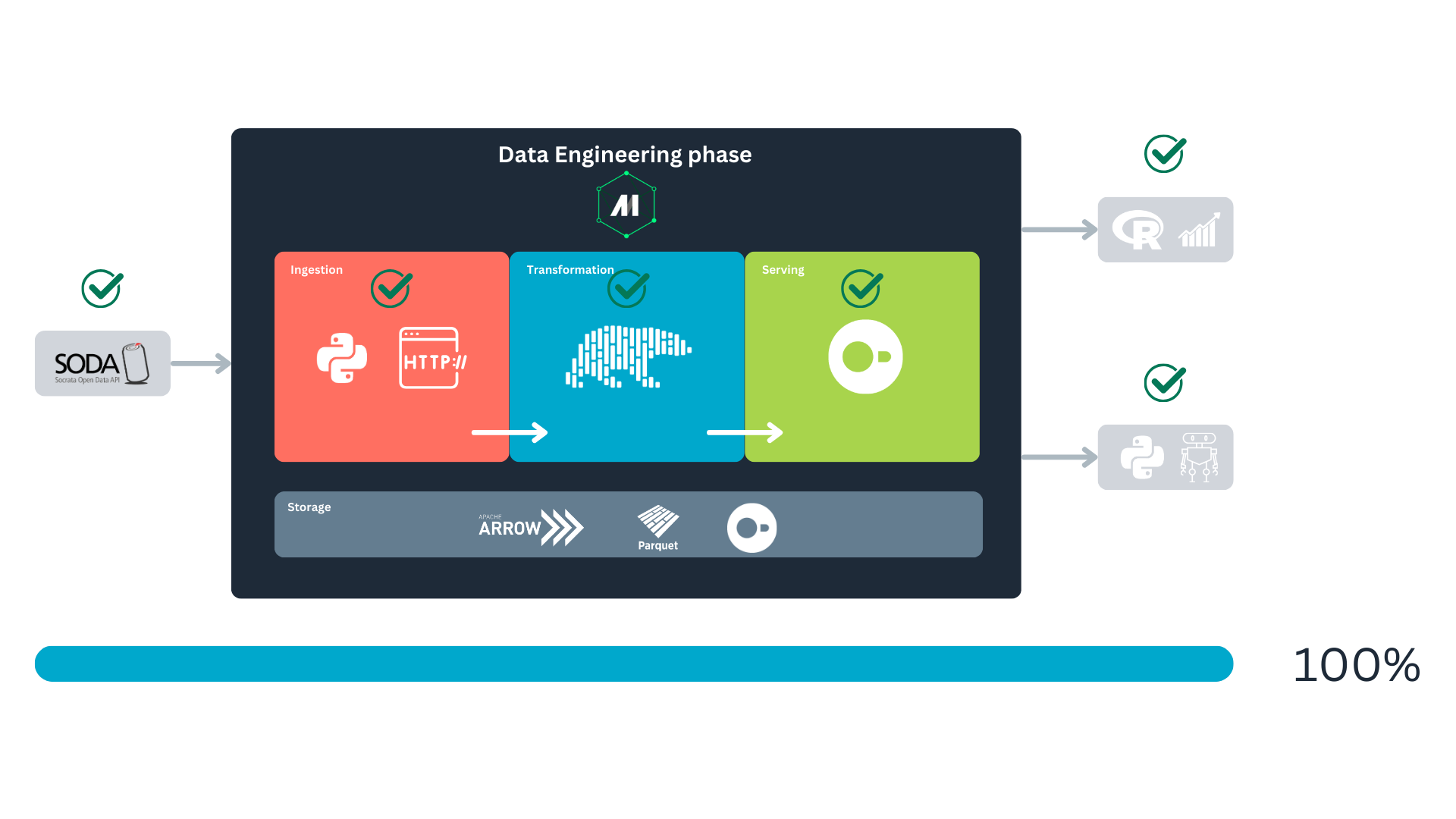
At this point, you must be overwhelmed and tired, but that’s because we have worked and implemented a whole data life cycle. Congratulation!
Recap
During this project, we did a lot. We started analyzing the source of our data and thinking about the best way to retrieve it. We coded a mechanism to fetch the data, transformed it with Polars, and then stored it on disk. Finally, we illustrated that the data we got is indeed helpful in answering real-life questions.
The data landscape is vast, with many appliances available for every task. In this project, we explored several modern tools to address a data engineering problem. However, it’s important not to limit yourself to these specific libraries. Each issue may require a different set of tools, but the key is to focus on the foundational principles of data engineering. The technical stack can be chosen later, but the core concepts will pave the way to finding practical solutions to your challenges.
Without more, I hope here you have learned a little and that you can apply some of these things in your tasks :)
About the polar bear in the header
It’s the Bonjour Bear, you can read more about the bear in Know Your Meme :)
Cited works and recommended readings
Kersten, T., Leis, V., Kemper, A., Neumann, T., Pavlo, A., & Boncz, P. (2018). Everything you always wanted to know about compiled and vectorized queries but were afraid to ask. Proceedings of the VLDB Endowment, 11(13), 2209-2222. https://doi.org/10.14778/3275366.3275370.
Lovelace, R., Nowosad, J., & Muenchow, J. (2025). Geocomputation with R (2nd ed.). Chapman and Hall/CRC. https://r.geocompx.org/.
Needham, M., Hunger, M., & Simons, M. (2024). DuckDB in Action. Manning Publications.
Reis, J., & Housley, M. (2022). Fundamentals of data engineering: Plan and build robust data systems. O’Reilly Media.
Citation
No citation is required, but if you found this project helpful, I’d greatly appreciate a mention! 😄
Acknowledgements
To Little Mai, my home office manager and editor-in-chief of “Paws-On Data.”

Contact
Have questions, suggestions, or just want to connect? Feel free to reach out!
- LinkedIn: José Pablo Barrantes
- BlueSky: doggofan77.bsky.social
Footnotes
According to their web page :)↩︎
There is no budget for a “scientist,” and at this point in history, there is no such thing as a “data engineer” in Latin America Iowa.↩︎
Please pretend that the tools existed at the time. I certainly wished for a data ecosystem like this, and I was in Latin America (Little Mai and I still are, and we’re loving it 🪇🐑).↩︎
I spent a few days debugging this and initially signaled Mage as the culprit, but in the end, the SODA API was responsible.↩︎
The process will get frozen at some point with no notifications or feedback.↩︎
Little Mai and I 🐑.↩︎
This occurs when the returned object is a data frame (Polars or Pandas). In this concrete case, that won’t happen since we’re returning a dictionary, but in the following blocks, it will be the case since the objects transferred will be Polars data frames. With dictionaries, serialization will still occur but in JSON format.↩︎
We can also use
.pl()to cast the results into a Polars data frame or.df()for a Pandas one.↩︎For instance, I should move the
fetch_batchfunction outside theload_data_from_apiloader. Defining functions within other functions is generally considered a bad practice, as it can make the code harder to read, test, and maintain.↩︎Repeat after me: “We love open source.”↩︎
We’ve found Manning a reliable editorial for technical books. Most of the time, their materials have high-quality content that is easy to digest. Highly recommended 👌.↩︎
DuckDB is listed as an explicit dependency in
pyproject.tomlusingduckdb>=1.5.2. In normal use,uv syncinstalls the resolved DuckDB version fromuv.lock.↩︎Please note that this is not a traditional exporter block; it could be a custom block. I chose the exporter type because it interacts with the local database and creates the table, even though no data is exported in an explicit manner.↩︎
Free Bird’s guitar solo starts playing in the background 🎸🎶🎶.↩︎
If you’ve had the pleasure to work with geospatial analysis before, you probably already know that CRSs are always awfully documented (i.e., not documentation at all). So, working with coordinates of less standard regions is a painful process full of guesses.↩︎
It is more to illustrate that DuckDB can be the source that feeds different systems. We already checked R, and we’re continuing with Python. You can follow with Power BI or Tableau if you want :)↩︎